ICLR 2026惊现SAM 3,分割一切的下一步:让模型理解「概念」
ICLR 2026惊现SAM 3,分割一切的下一步:让模型理解「概念」说出概念,SAM 3 就明白你在说什么,并在所有出现的位置精确描绘出边界。 Meta 的「分割一切」再上新? 9 月 12 日,一篇匿名论文「SAM 3: SEGMENT ANYTHING WITH CONCEPTS」登陆 ICLR 2026,引发网友广泛关注。
来自主题: AI技术研报
7707 点击 2025-10-13 16:03
 搜索
搜索
说出概念,SAM 3 就明白你在说什么,并在所有出现的位置精确描绘出边界。 Meta 的「分割一切」再上新? 9 月 12 日,一篇匿名论文「SAM 3: SEGMENT ANYTHING WITH CONCEPTS」登陆 ICLR 2026,引发网友广泛关注。
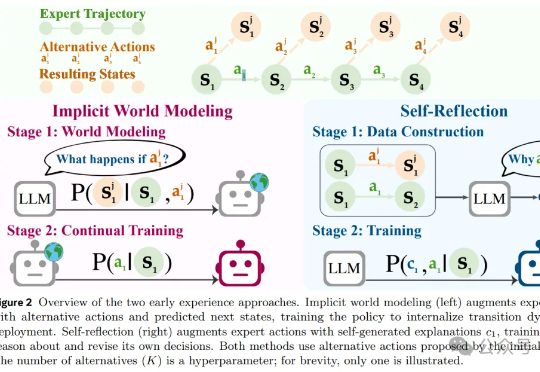
风雨飘摇中的Meta,于昨天发布了一篇重量级论文,提出了一种被称作「早期经验」(Early Experience)的全新范式,让AI智能体「无师自通」,为突破强化学习瓶颈提供了一种新思路。
那个拒绝了小扎15亿美元薪酬包的机器学习大神,还是加入Meta了。OpenAI前CTO Mira Murati创业公司Thinking Machines Lab证实,联创、首席架构师Andrew Tulloch已经离职去了Meta。

夸克 AI 眼镜看起来就是一副普通眼镜,平平无奇,那它在汇聚了阿里AI 和应用生态后,到底能带来什么新的体验?APPSO 带你看看👇第一印象:它首先是一副好戴的眼镜前段时间在我们体验 Meta Ray-Ban Display 的视频里,引起用户互动最高的一个细节大大出乎了我们的意料:数主播扶了多少次眼镜。
MGX,全称 MetaGPT X,是 DeepWisdom 推出的多智能体平台,定位是“24/7 的 AI 开发团队”。它的特别之处在于,你只需要输入需求,系统就会自动生成一支虚拟团队。
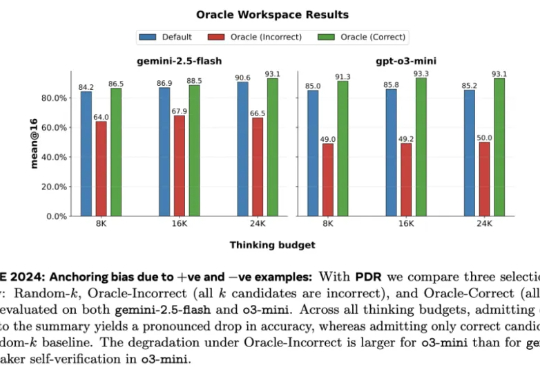
Meta 超级智能实验室、伦敦大学学院、Mila、Anthropic 等机构的研究者进行了探索。从抽象层面来看,他们将 LLM 视为其「思维」的改进操作符,实现一系列可能的策略。研究者探究了一种推理方法家族 —— 并行 - 蒸馏 - 精炼(Parallel-Distill-Refine, PDR),

您修过Bug吗?在Vibe coding的时代之前,当程序员遇到自己写的 Bug 时,通常能顺着自己的思路反推问题所在。但当面对 AI 生成的 Bug 时,情况变得复杂得多,我们不清楚 AI 的“思考
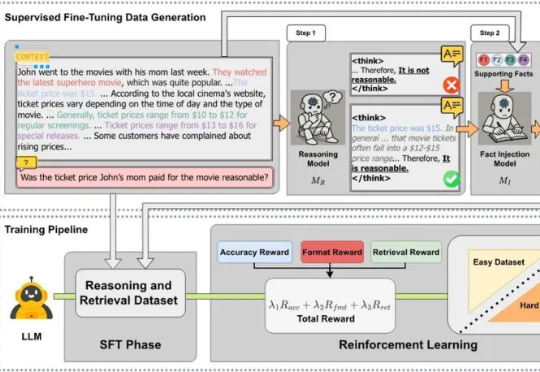
近日,来自 MetaGPT、蒙特利尔大学和 Mila 研究所、麦吉尔大学、耶鲁大学等机构的研究团队发布 CARE 框架,一个新颖的原生检索增强推理框架,教会 LLM 将推理过程中的上下文事实与模型自身的检索能力有机结合起来。该框架现已全面开源,包括训练数据集、训练代码、模型 checkpoints 和评估代码,为社区提供一套完整的、可复现工作。

早在 2021 年,研究人员就已经发现了深度神经网络常常表现出一种令人困惑的现象,模型在早期训练阶段对训练数据的记忆能力较弱,但随着持续训练,在某一个时间点,会突然从记忆转向强泛化。

我惊! 图灵奖得主、AI三巨头之一的LeCun在Meta待得是如坐针毡。 Yann LeCun已经直接跟同事表示,自己可能会辞去FAIR首席科学家的职务。