# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近,关于大模型推理的测试时间扩展(Test time scaling law )的探索不断涌现出新的范式,包括① 结构化搜索结(如 MCTS),② 过程奖励模型(Process Reward Model )+ PPO,③ 可验证奖励 (Verifiable Reward)+ GRPO(DeepSeek R1)。然而,大模型何时产生 “顿悟(Aha Moment)” 的机理仍未明晰。近期多项研究提出推理模式(reasoning pattern)对于推理能力的重要作用。类似的,本研究认为
大模型复杂推理的能力强弱本质在于元思维能力的强弱。
所谓 “元思维” (meta-thinking),即监控、评估和控制自身的推理过程,以实现更具适应性和有效性的问题解决,是智能体完成长时间复杂任务的必要手段。大语言模型(LLM)虽展现出强大推理能力,但如何实现类似人类更深层次、更有条理的 "元思维" 仍是关键挑战。
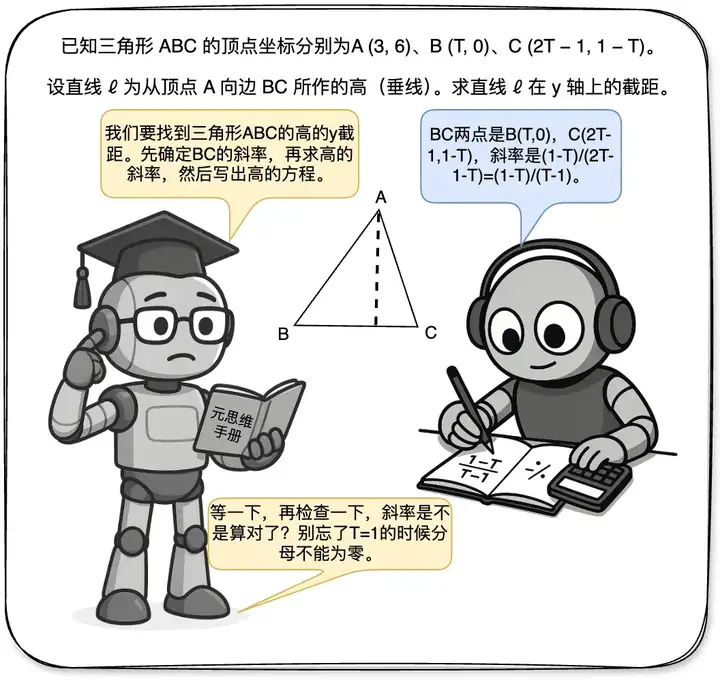
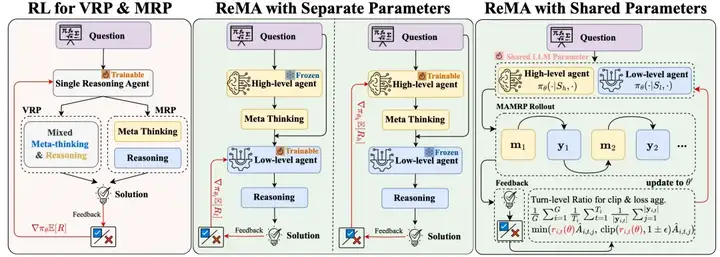
上图通过两台机器人求三角形高线的截距的解决样例,直观展示了元思维与推理的分工:推理机器人执行计算,元思维机器人则在关键节点介入进行规划、拆解或纠错。基于这个动机,本研究提出从多智能体的角度建模并解决这个问题并引入强化元思维智能体(Reinforced Meta-thinking Agents, 简称 ReMA)框架,利用多智能体间的交互来建模大模型推理时的元思维和推理步骤,并通过强化学习鼓励整个系统协同思考如何思考,以兼顾探索效率与分布外泛化能力。

当前,提升大模型推理能力的研究主要分为两种思路:
一是构造式的方法:通过在结构化的元思维模板上采样与搜索构造数据进行监督微调,但这类方法往往只是让模型记住了这种回答范式,而没有利用模型内在的推理能力进行灵活探索以发现模型本身最适合的元思维模式,因此难以泛化到分布外的问题集上;
二是 Deepseek R1 式的单智能体强化学习(SARL)方法:通过引入高质量退火数据获得具备一定的混合思维能力的基础模型后,直接使用规则奖励函数进行强化学习微调,习得混合元思维和详细推理步骤。但这类方法通常依赖强大的基础模型,对于能力欠缺的基础模型来说在过大的动作空间内无法进行高效探索,且不用说可能导致的可读性差等问题。
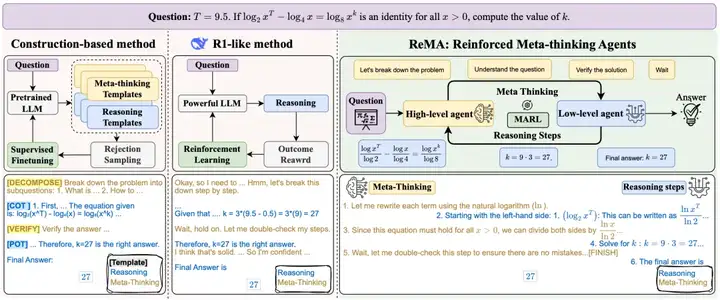
图一:ReMA框架与现有大模型复杂推理训练框架对比
针对这些挑战,ReMA 框架采取了一套全新的解决思路,将复杂的推理过程解耦为两个层级化的智能体:

这两个智能体通过具有一致目标的迭代强化学习过程进行探索和协作学习。这种多智能体系统(MAS)的设计,将单智能体强化学习的探索空间分散到多个智能体中,使得每个智能体都能在训练中更结构化、更有效地进行探索。ReMA 通过这种方式来平衡了泛化能力和探索效率之间的权衡。
ReMA 的生成建模
本研究首先给出单轮多智能体元思维推理过程(Multi-Agent Meta-thinking reasoning process,MAMRP)的定义。
在单轮交互场景下,当给定一个任务问题时,元思维智能体会对问题进行宏观分析和必要拆解,产生求解计划,而推理智能体会根据元思维的逐步指令完成任务内容。具体来说,给定问题,元思维智能体首先给出元思维,接着推理智能体给出问题求解,该过程如下所示:
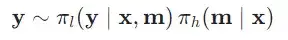
而在多轮交互场景中,元思维智能体给出的元思维可以以一种更加均匀的方式加入到整个思考过程中,元思维智能体可以显式地对求解的过程进行计划、拆解、反思、回溯和修正,其交互历史会不断叠加直至结束。类似的,本研究可以给出多轮 MAMRP 的定义,该过程如下所示:
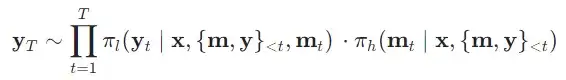
整个系统的求解过程可以用以下有向图来直观理解:
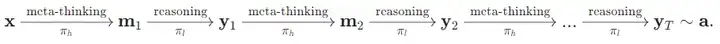
图二:不同算法框架的训练方式对比
单轮 ReMA 的训练
单轮场景下,考虑两个智能体和 ,团队通过迭代优化的方式最大化两个智能体各自的奖励,从而更新智能体们各自的权重:
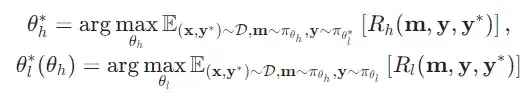
其中每个智能体的奖励函数分别考虑了总体回答正确性与各自的格式正确性。对于策略梯度的更新算法,本研究使用目前主流的 GRPO 和 REINFORCE++ 来节省显存和加速训练。
多轮 ReMA 的训练
在扩展到多轮场景下时,为了提升计算效率和系统可扩展性,团队做了如下改变:
(1)首先是通过共享参数的方式降低维护两份模型参数的部署开销,同时简化调度两份模型参数的依赖关系,提高效率。具体来说,本研究使用不同的角色的系统提示词来表示不同智能体的策略
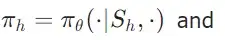
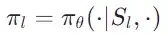
,在优化时同时使用两个智能体的采样数据进行训练,更新一份参数。
(2)其次是针对多轮交互场景的强化学习,不同于本研究将每一轮的完整输出定义为一个动作,通过引入轮次级比率(turn-level ratio)来进行 loss 归一化与剪切, 具体优化目标如下所示:
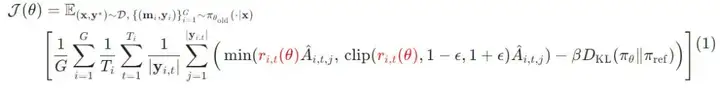
其中:
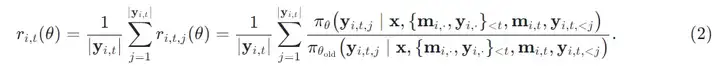
通过这样的方式,在多轮训练的过程中,能够消除 token-level loss 对于长度的 bias,另外通过考虑单轮所有 token 的整体裁切,可以一定程度上稳定训练过程。
单轮 ReMA 的实验
首先团队在单轮设定上对比了一般 CoT 的 Vanila Reasoning Process (VRP),以及其 RL 训练后的结果 VRP_RL, MRP_RL。团队在多个数学推理基准(如 MATH, GSM8K, AIME24, AMC23 等)和 LLM-as-a-Judge 基准(如 RewardBench, JudgeBench)上对 ReMA 进行了领域内外泛化的广泛评估。在数学问题上,团队使用了 MATH 的训练集(7.5k)进行训练,在 LLM-as-a-Judge 任务上则将 RewardBench 按子类比例划分为了 5k 训练样本和 970 个测试样本进行训练和领域内测试。
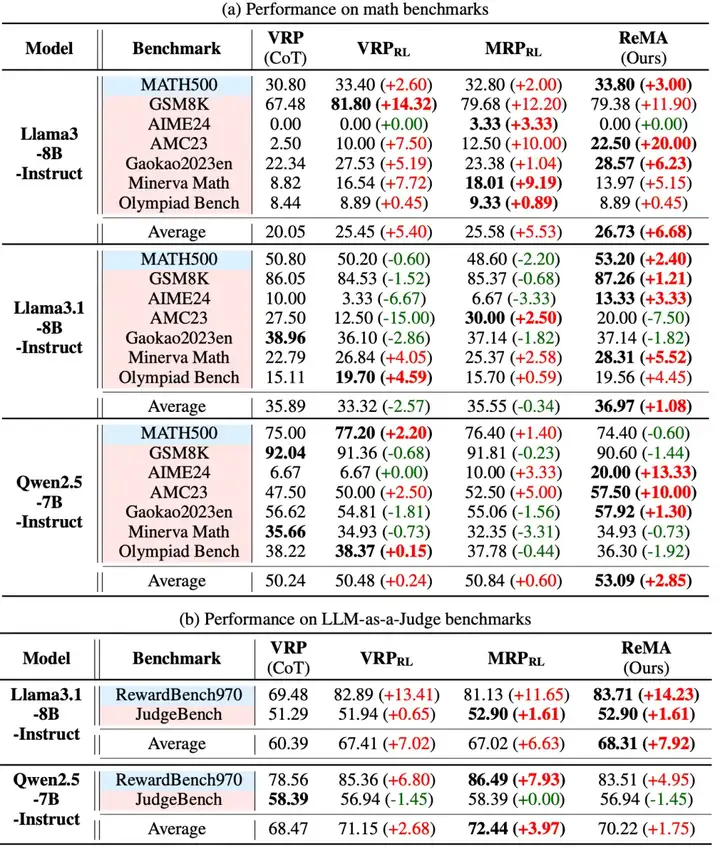
表一:单轮ReMA的实验对比
结果显示,在多种骨干预训练模型(如 Llama-3-8B-Instruct, Llama-3.1-8B-Instruct, Qwen2.5-7B-Instruct)上,ReMA 在平均性能上一致优于所有基线方法。特别是在分布外数据集上,ReMA 在大多数基准测试中都取得了最佳性能,充分证明了其元思索机制带来的卓越泛化能力。例如,在使用 Llama3-8B-Instruct 模型时,ReMA 在 AMC23 数据集上的性能提升高达 20%。
为了证明 ReMA 中多智能体系统的引入对于推理能力的训练有益,团队在单轮设定下分别对二者的强化学习训练机制进行了消融实验。
问题一:元思维是否可以帮助推理智能体进行强化学习训练?
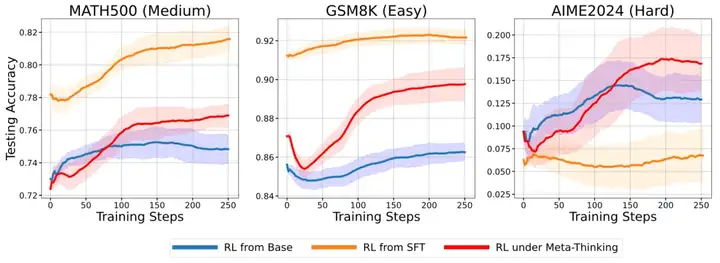
团队分别对比了三种强化学习训练策略,RL from base 采用了基础模型直接进行 RL 训练;RL from SFT 在 RL 训练开始前先用 GPT-4o 的专家数据进行 SFT 作为初始化;RL under Meta-thinking 则在 RL 训练时使用从 GPT-4o 生成的元思维数据 SFT 过后的元思维智能体提供高层指导。
图三展示了训练过程中三种不同难度的测试集上的准确率变化趋势,实验结果证明了元思维对于推理模型的强化学习具有促进作用,尤其是在更困难的任务上具有更好的泛化性。
问题二:LLM 是否能够通过强化学习演化出多样的元思维?
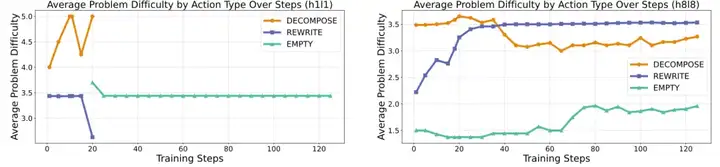
图四:不同规模的元思维智能体的强化学习训练演化过程
接着团队探索了不同规模的元思维智能体的强化学习训练演化过程,团队设计了一个可解释性动作集合。通过让模型输出 JSON 格式的动作(先确定动作类型(DECOMPOSE,REWRITE,EMPTY),再输出相应的内容),以实现对模型输出动作类型的监控。图四展示了三种动作类型对应的问题难度在训练中的变化,实验发现,在小模型上进行训练时(Llama3.2-1B-Instruct),元思维策略会快速收敛到输出简单策略,即 “什么都不做”;而稍大一些的模型(如 Llama3.1-8B-Instruct)则能够学会根据问题难度自适应的选择不同的元思维动作。这个结果也意味着,现在越来越受到关注的自主快慢思考选择的问题,一定程度上可以被 ReMA 有效解决。
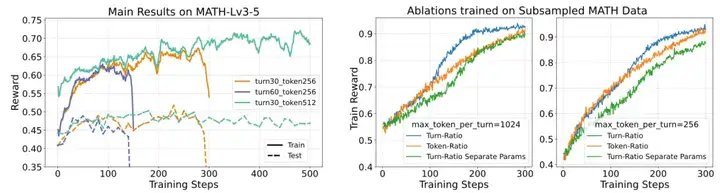
图五:多轮ReMA的实验结果
最后,团队扩展到多轮设定下进行了实验。首先,由于大多数语言模型本身不具备将问题拆解成多轮对话来完成的能力,团队先从 LIMO 数据集中转换了 800 条多轮 MAMRP 的样本作为冷启动数据,接着使用 SFT 后的权重进行强化学习训练。图五左侧展示了在 MATH level 3-5 (8.5k)数据集上的训练曲线和在七个测试集上的平均准确率。团队发现了以下结论:
图五右侧展示了前文中提出的两个改进(共享参数更新和轮次级比率)对于多轮训练的影响,团队采样了一个包含所有问题类型的小数据集以观察算法在其上的收敛速度和样本效率。不同采样设定下的实验结果均表明该方案能够有效提升样本效率。
总的来说,团队尝试了一种新的复杂推理范式,即使用两个层次化的智能体来显式区分推理过程中的元思维,并通过强化学习促使他们协作完成复杂推理任务。团队在单轮与多轮的实验上取得了一定的效果,但是在多轮训练的中还需要进一步解决训练崩溃的问题。这表明目前基于 Deterministic MDP 的训练流程也许并不适用于 Stochastic/Non-stationary MDP,对于这类问题的数据、模型方面还需要有更多的探索。
文章来自于“机器之心”,作者“万梓煜”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
