AI Agent最新「Memory」综述 |多所顶尖机构联合发布
AI Agent最新「Memory」综述 |多所顶尖机构联合发布就在昨天,新加坡国立大学、中国人民大学、复旦大学等多所顶尖机构联合发布了一篇AI Agent 记忆(Memory)综述。
来自主题: AI技术研报
9958 点击 2025-12-17 09:21
 搜索
搜索
就在昨天,新加坡国立大学、中国人民大学、复旦大学等多所顶尖机构联合发布了一篇AI Agent 记忆(Memory)综述。

国内记忆框架首开源,企业实战已上线运行。在海外巨头已经将“记忆系统”提升到基础设施层的同时,红熊AI便是其中之一。公司成立于2024年,围绕多模态大模型与记忆科学开展研发,并将这些能力用于为企业提供智能客服、营销自动化与AI智能体服务。

在 Text-to-Video / Image-to-Video 技术突飞猛进的今天,我们已经习惯了这样一个常识: 视频生成的第一帧(First Frame)只是时间轴的起点,是后续动画的起始画面。

记忆,或是 AI 从「即时回答工具」迈向「个性化超级助手」的关键突破
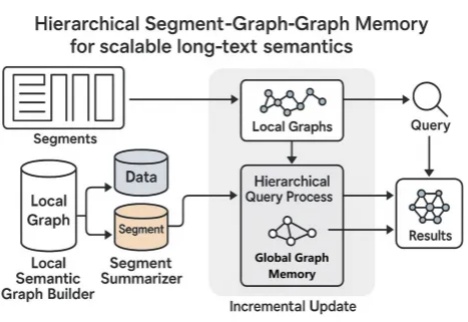
当你阅读《红楼梦》《哈利·波特》《百年孤独》等长篇小说时,读着读着可能就忘记前面讲了什么,有时还会搞混人物关系。AI 在阅读长文章的时候也存在类似问题,当文章太长时它也会卡主,要么读得特别慢,要么记不住前面的内容。
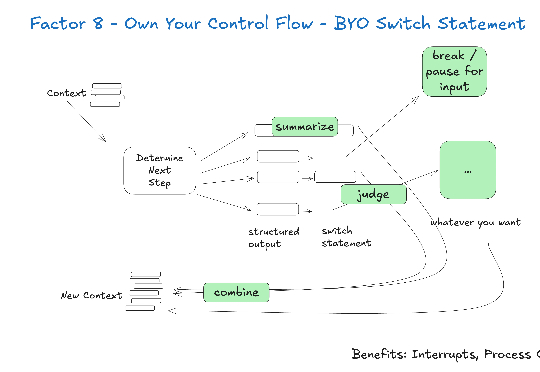
最近半年,我阅读了业界关于 AI Agent 的工程实践:Anthropic 的 Context Engineering 论文、Manus 的工程分享、Cline 的 Memory Bank 设计等。同时自己也一直在做跟 AI Agent 相关的项目,如:Jta[1](开源的翻译 Agent,基于 Agentic Workflow)。

谷歌在第三天发布了《上下文工程:会话与记忆》(Context Engineering: Sessions & Memory) 白皮书。文中开篇指出,LLM模型本身是无状态的 (stateless)。如果要构建有状态的(stateful)和个性化的 AI,关键在于上下文工程。

智源研究院(BAAI)、Spin Matrix、乐聚机器人与新加坡南洋理工大学等联合提出了一个全新的终身记忆系统——RoboBrain-Memory。RoboBrain-Memory是全球范围内首个专为全双工、全模态模型设计的终身记忆系统,旨在解决具身智能体在真实世界的复杂交互问题,不仅支持实时音视频中多用户身份识别与关系理解,还能动态维护个体档案与社会关系图谱,从而实现类人的长期个性化交互。

我深入研究了 Supermemory 的技术方案后,发现它和市面上其他记忆解决方案有本质区别。大多数所谓的"记忆"系统,本质上只是一个数据库,提供基本的增删改查功能。你可以保存一个实体,给它设定用户范围,然后查询出来。这很有用,但这只是基础功能,任何数据库都能做到。

想象这样一个场景: 一个AI智能体在帮你处理邮件,一封看似正常的邮件里,却用一张图片的伪装暗藏指令。AI在读取图片时被悄然感染,之后它发给其他AI或人类的所有信息里,都可能携带上这个病毒,导致更大范围的感染和信息泄露。