
突然袭击!刚刚,Meta超级智能团队首个大模型 Muse Spark 来了
突然袭击!刚刚,Meta超级智能团队首个大模型 Muse Spark 来了刚刚,Meta 重金组建的超级智能实验室(SML)交卷!这也是年轻华人 Alexandr Wang 带领该团队后,交出的首份成绩。全新自研模型 Muse Spark 上线。
来自主题: AI资讯
9046 点击 2026-04-09 09:26
 搜索
搜索
刚刚,Meta 重金组建的超级智能实验室(SML)交卷!这也是年轻华人 Alexandr Wang 带领该团队后,交出的首份成绩。全新自研模型 Muse Spark 上线。

别人还在卷单点能力,Agnes已经把文本Agent、图像、视频和办公自动化打包进开发者工具箱:1美元「养龙虾」,外加图像、视频、PPT一条龙,给出的不是零散的能力点,而是一整套AI生产力。

在构建多Agent系统(Multi-Agent Systems)时,让几个Agent互相“对话”并不难,但要让它们在局部状态不一致的情况下,敲定一个全局唯一的决策,也就是达成“一致”(Agree)或“共识(Consensus)”,却是一个极具挑战的工程难题,您可能会问为什么,这有何难?

在会上,昆仑万维旗下天工 AI 重磅发布了全新 AI 游戏世界模型 Matrix-Game 3.0、AI 视频大模型 SkyReels V4 和 AI 音乐大模型 Mureka V9,在继续强化 AIGC 理解与生成能力的同时,进一步推进 AI 对物理世界的建模与仿真。
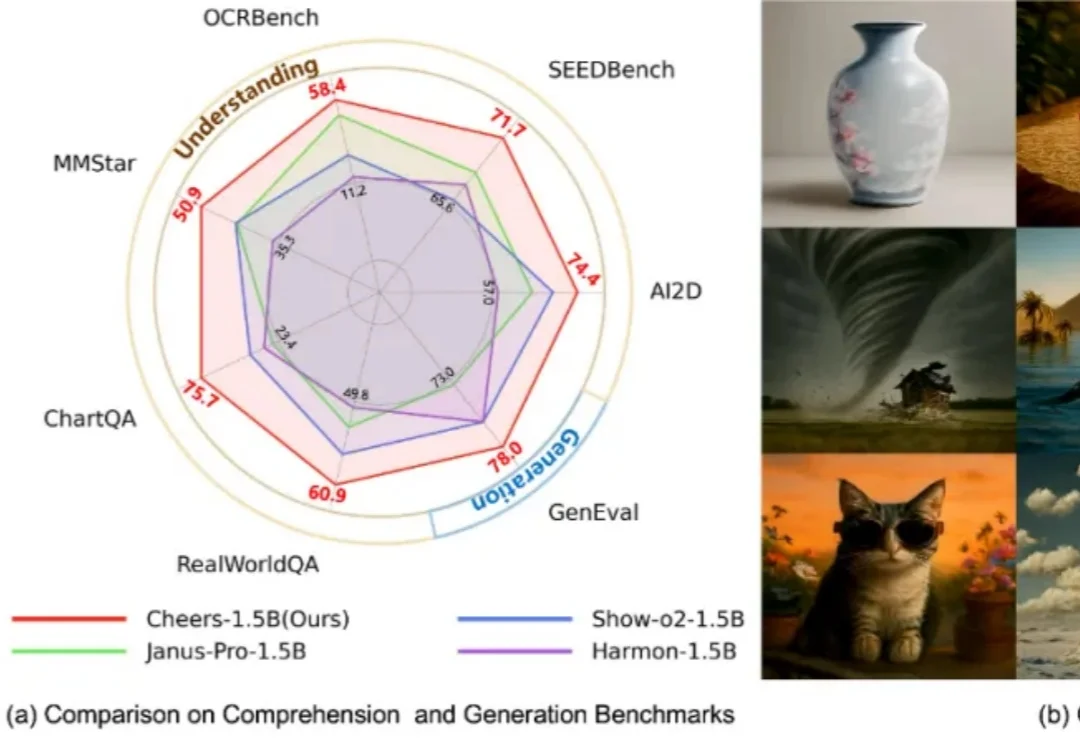
过去几年,多模态模型在理解任务上快速演进,图像问答、OCR、视觉推理、跨模态对话等能力不断提升;与此同时,图像生成模型也在视觉质量、指令遵循和细节表达上持续突破。下一步一个自然的问题是:能否用同一个模型,同时做好理解与生成?这正是统一多模态模型(Unified Multimodal Models, UMMs)正在回答的问题。

AI音乐变天了!Mureka V8强势登顶AA榜,包揽人声与器乐双项冠军。而这仅仅是开始,下一代Mureka V9已在路上了!

ACE 的起点,并不是把音乐生成做成一个更轻的娱乐玩具,而是从专业创作工作流里切进去。ACE Studio 2.0 于 2025 年 12 月正式发布,产品形态也从 AI vocal workstation 进一步扩展为 all in one AI music studio,开始把 AI 歌声、乐器、生成、编辑与 DAW 协同整合成一个AI 音乐创作系统。
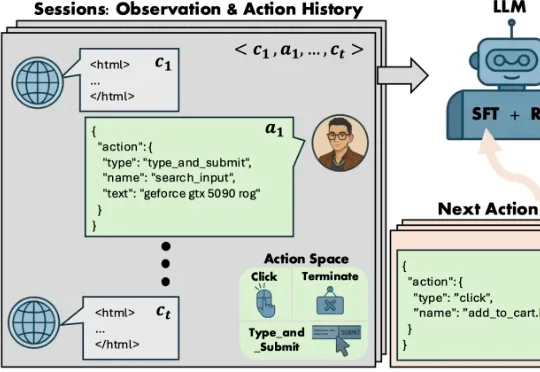
传统的 AI 购物助手更像是一个任务完成机器:接到指令,搜索,下单。他们或许能跑通流程,却完全无法理解用户为何在最后一刻因为一条关于 “夹耳朵” 的差评而放弃支付。简而言之,传统的电商 Agent 只是任务导向的(task-oriented),而不是模拟导向的(simulation-oriented)。为此,来自亚马逊(Amazon)的研究团队提出了名为 Shop-R1 的训练框架 。

Transformer不保?今天,CMU普林斯顿原班人马杀回,新一代开源架构Mamba-3震撼降临。15亿参数战力爆表,性能比Transformer飙升4%。

今天上午,AI Agent创企MuleRun(骡子快跑)团队发布MuleRun 2.0,该产品是一个可自我进化的个人AI Agent助手。Mulerun创始人兼CEO陈宇森分享称,MuleRun的上手门槛更低,可以在给定目标的前提下主动工作,具有0门槛使用、极高安全性、稳定性、售后完善、自进化能力、24小时在线、主动性等优势。