DeepSeek V4最大的遗憾
DeepSeek V4最大的遗憾DeepSeekV4的技术报告里有mHC,有CSA,有HCA,有Muon,有FP4……唯独没有Engram。Engram在今年1月由DeepSeek和北大联合开源,主要研究大模型的记忆与效率问题。
来自主题: AI技术研报
7642 点击 2026-05-03 22:45
 搜索
搜索
DeepSeekV4的技术报告里有mHC,有CSA,有HCA,有Muon,有FP4……唯独没有Engram。Engram在今年1月由DeepSeek和北大联合开源,主要研究大模型的记忆与效率问题。

今天上午,DeepSeek V4 发布,直接把这个大模型疯狂更新月推向了最高潮。不过在我翻看 V4 的技术报告的时候,在训练层面看到了一个被大部分人滑过去的名词:Muon 优化器。
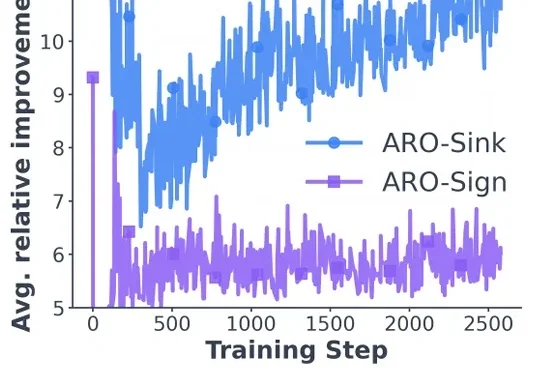
如果你在过去一年关注过大模型训练的技术,大概率听过 Muon 这个名字 —— 这个在月之暗面 K2 模型的相关讨论中走红的优化器,被视为是可能挑战 Adam 的新秀。它的思路很直接:对动量矩阵进行正交化,让各个奇异方向上的更新速率一致,提升训练效率。

在 LLM 优化领域,有两个响亮的名字:Adam(及其变体 AdamW)和 Muon。

2025年前盛行的闭源+重资本范式正被DeepSeek-R1与月之暗面Kimi K2 Thinking改写,二者以数百万美元成本、开源权重,凭MoE与MuonClip等优化,在SWE-Bench与BrowseComp等基准追平或超越GPT-5,并以更低API价格与本地部署撬动市场预期,促使行业从砸钱堆料转向以架构创新与稳定训练为核心的高效路线。
未中顶会,没有发表arXiv,一篇博客却成为OpenAI速通票。天才科学家Keller Jordan仅凭Muon优化器博客加入OpenAI。甚至,它可能被用于训练下一代超级模型GPT-5。

省一半算力跑出2倍效果,月之暗面开源优化器Muon,同预算下全面领先。
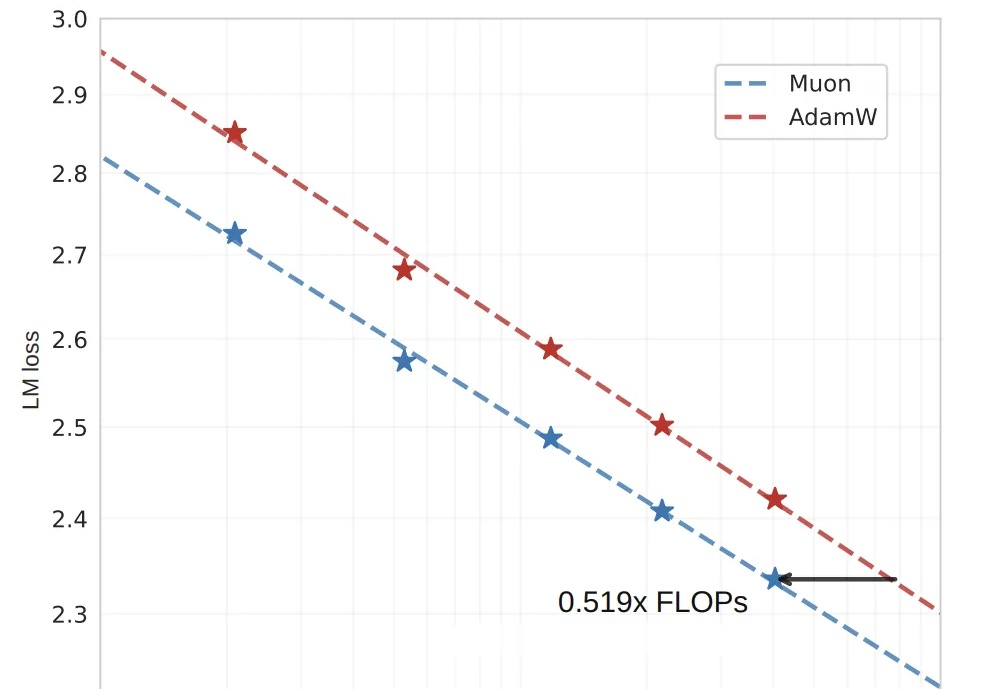
算力需求比AdamW直降48%,OpenAI技术人员提出的训练优化算法Muon,被月之暗面团队又推进了一步!