
NVIDIA团队让编程Agent接管真实机器人实验,成功率达99%
NVIDIA团队让编程Agent接管真实机器人实验,成功率达99%自动化研究,这一次真正走出代码沙盒,进入了真实的物理世界。
来自主题: AI技术研报
8485 点击 2026-06-18 16:31
 搜索
搜索
自动化研究,这一次真正走出代码沙盒,进入了真实的物理世界。
刚刚,田渊栋创业公司,交出了首个研究成果。田渊栋在X上宣布,其创立的Recursive,在NVIDIA官方的GPU kernel优化榜SOL-ExecBench上拿下了整体和四个子类别的SOTA。

在具身智能训练中,“把计算全部塞进GPU”似乎成了唯一的提速密码,机器人运控并行训练的框架,IsaacLab、MuJoCoPlayground、mjlab都默认遵循这一范式,这些系统都牢牢绑定在NVIDIA生态中。

在上午 11 点开始的英伟达 GTC Taibei 2026 大会现场,黄仁勋拿出了英伟达与微软联手打造的 PC 产品。在细数了将近 1 个小时已有成果之后,黄仁勋终于开讲今天的重头戏:一款迄今为止全球性能最强、能效最高的轻薄型 Windows PC。

5 月下旬,NVIDIA 联合清华大学、多伦多大学和 Vector Institute 发布 Gamma-World,共一第一为清华大学电子系博士刘芳甫,核心 Research 方向是世界模型和空间智能。
近日,垂直于招投标领域的 AI 科技领军企业“深入云境”正式宣布:旗下核心产品 “云境标书AI” 成功入选 NVIDIA 初创加速计划(NVIDIA Inception)。这一里程碑式的进展,标志着云境标书AI在技术创新性、行业应用前景及商业潜力方面获得了全球顶级算力与AI生态巨头的权威认可。
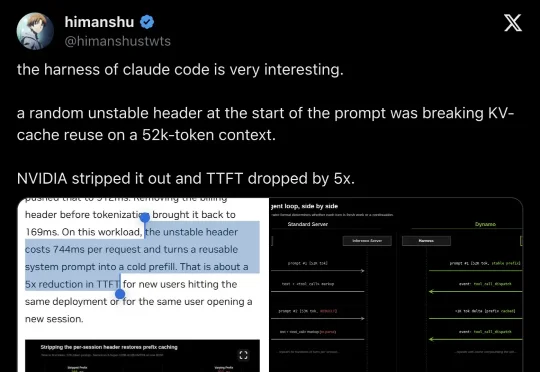
NVIDIA Dynamo 团队发现,Claude Code 向自定义端点发送请求时,prompt 最前面会带一行 session-specific billing header。这行 header 每个 session 都变,导致 52K token 的稳定前缀在 KV cache 中无法复用——TTFT 从 168ms 飙到 912ms。Dynamo 加了一个 `

MoE模型的稀疏激活本是优势,却常陷通信瓶颈。NVIDIA以软件为利剑,通过程序化依赖启动和全对全通信革新,在三个月内将GB200的单GPU吞吐提升2.8倍,真正释放Blackwell硬件潜力。
谷歌还在闭源守宝,NVIDIA已把Lyra 2.0全开源:35步去噪变4步,2D图片直出3D高斯泼溅+网格。社交狂欢背后,是对具身AI仿真的巨大潜力——以后造世界,不用再去真实世界采数据了。

由 NVIDIA 支持的 Vast Data (一家为人工智能任务开发数据存储软件的公司)表示,已筹集约 10 亿美元,估值超过三倍增至 300 亿美元。