NeurIPS 2025 | 英伟达发布Nemotron-Flash:以GPU延迟为核心重塑小模型架构
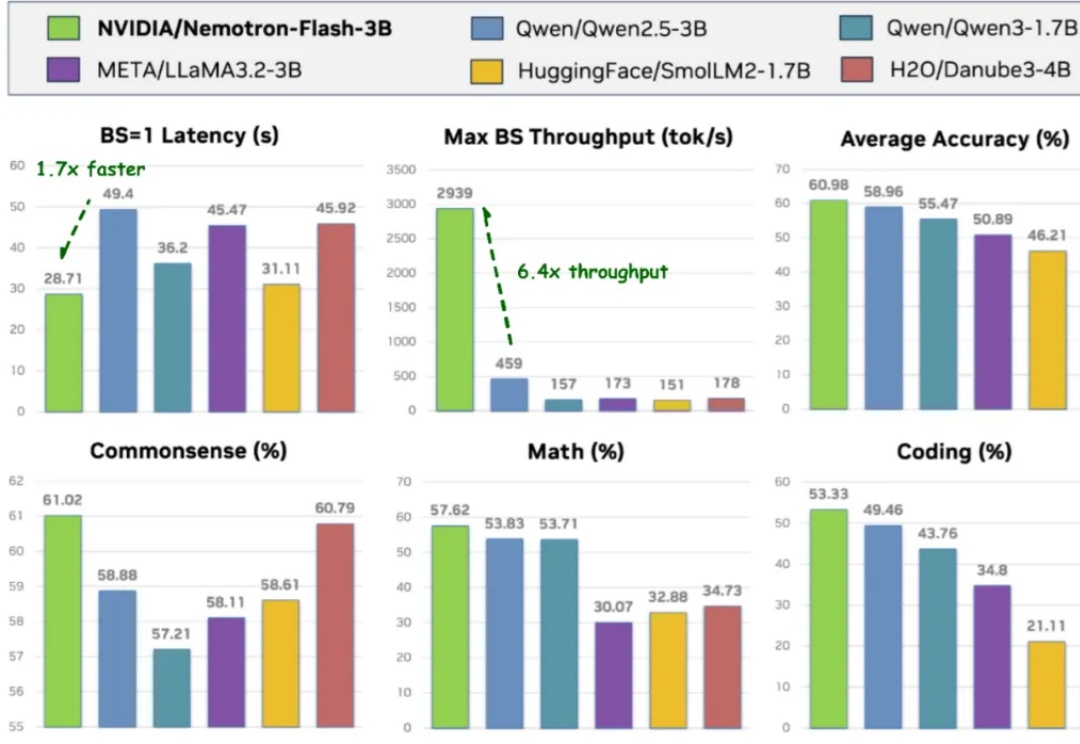
NeurIPS 2025 | 英伟达发布Nemotron-Flash:以GPU延迟为核心重塑小模型架构导读 过去两年,小语言模型(SLM)在业界备受关注:参数更少、结构更轻,理应在真实部署中 “更快”。但只要真正把它们跑在 GPU 上,结论往往令人意外 —— 小模型其实没有想象中那么快。
来自主题: AI技术研报
9094 点击 2025-12-01 10:09
 搜索
搜索
导读 过去两年,小语言模型(SLM)在业界备受关注:参数更少、结构更轻,理应在真实部署中 “更快”。但只要真正把它们跑在 GPU 上,结论往往令人意外 —— 小模型其实没有想象中那么快。