NeurIPS 2025 | 上下文元学习实现不微调跨被试脑活动预测
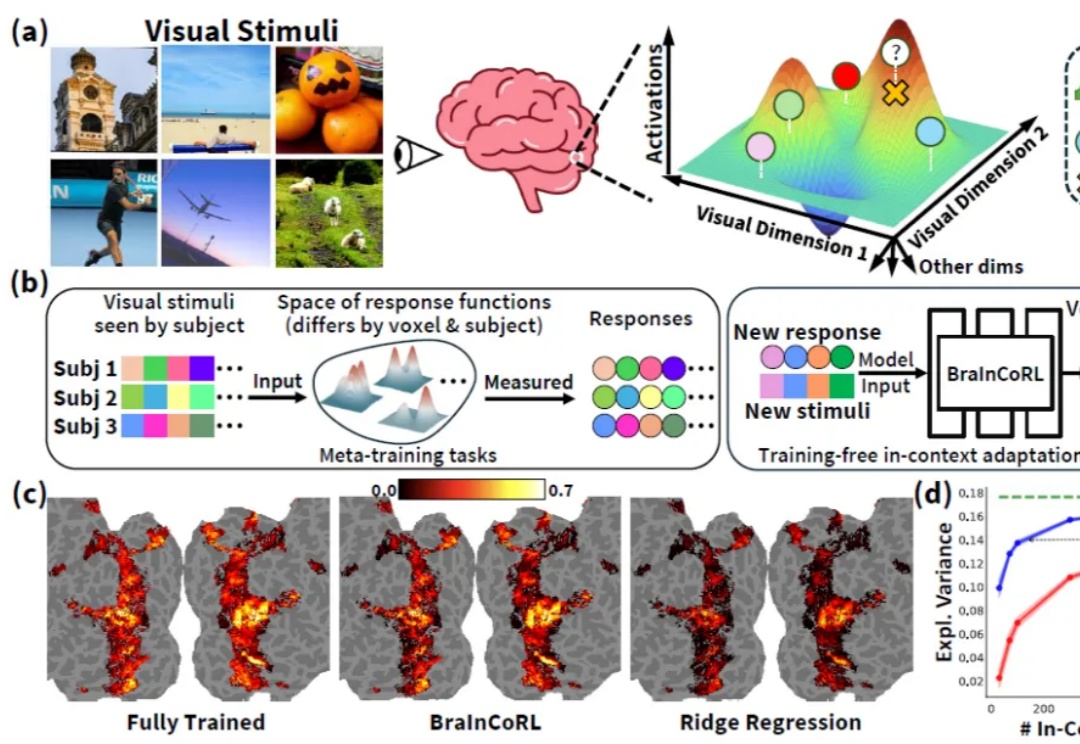
NeurIPS 2025 | 上下文元学习实现不微调跨被试脑活动预测人类高级视觉皮层在个体间存在显著的功能差异,而构建大脑编码模型(brain encoding models)—— 即能够从视觉刺激(如图像)预测人脑神经响应的计算模型 —— 是理解人类视觉系统如何表征世界的关键。传统视觉编码模型通常需要为每个新被试采集大量数据(数千张图像对应的脑活动),成本高昂且难以推广。
来自主题: AI技术研报
10885 点击 2025-11-19 15:21