
北约将活蟑螂的神经接入AI,化身无孔不入的赛博格侦察兵
北约将活蟑螂的神经接入AI,化身无孔不入的赛博格侦察兵活体蟑螂变身「赛博侦察兵」!德国公司利用神经接口和 AI 背包,将电子系统与昆虫躯体暴力缝合。它们能潜入无人机进不去的复杂绝境,更试图以生物繁殖代替工业制造,科技与军事的边界正被恐怖打破。
来自主题: AI资讯
9894 点击 2026-03-13 11:57
 搜索
搜索
活体蟑螂变身「赛博侦察兵」!德国公司利用神经接口和 AI 背包,将电子系统与昆虫躯体暴力缝合。它们能潜入无人机进不去的复杂绝境,更试图以生物繁殖代替工业制造,科技与军事的边界正被恐怖打破。

谷歌发布首个原生全模态 Embedding 模型 Gemini Embedding 2!它将文本、图、音视频及 PDF 无损融于统一向量空间,实现跨越五大模态的直接检索。这极大降低了架构成本,赋予了 AI 真正连贯的「记忆」,是重塑 AI 基建的里程碑。

生物研发进步提速长期受制于海量人工试错。恩和首发全球生物制造物理 AI 平台 SAION,打破 AI 仅限虚拟辅助的痛点。最大惊喜是它「长出了手脚」,能自主设计并直接调度设备执行真实实验,实现闭环进化!其生物科研表现全面超越 GPT 与斯坦福 Biomni,实现 SOTA。AI 科学家终于下场干活了!

港科大团队提出音频生成统一模型AudioX,只需一个模型,就能从文本、视频、图像等任意模态生成高质量音效和音乐,在多项基准上超越专家模型。团队同时开源了700万样本的细粒度标注数据集IF-caps与可控T2A评测基准T2A-bench,并在该基准上大幅领先现有方法。论文已被ICLR 2026接收。

导读:近日,位于中关村的深度机智全球首次使用全新范式——人类学习,在多个国际 Benchmark 上取得 SOTA,史无前例地使用全新架构(仅使用人类第一视角数据、零真机数据)击败 Physical Intelligence 和英伟达等头部巨头二十多个百分点,并在两会开幕首日被央视报道。

如果科研中的文献阅读、代码演进、实验验证都可以由智能体自主完成,科学发现的方式会被重新定义吗?自主科研智能体(Autonomous Research Agent)的兴起,正在把这一设想带入现实:科学家有望回归科学品味和探索源头,智能体承担科研全链路的繁琐工作,两者在人机协同的闭环中共探新的重大科研突破。
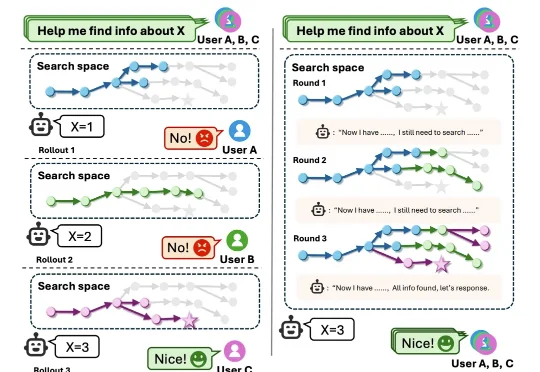
来自东南大学、微软亚洲研究院等机构的研究团队提出了一种全新的解决方案——Re-TRAC(REcursive TRAjectory Compression),这个框架让 AI 智能体能够「记住」每次探索的经验,在多个探索轨迹之间传递经验,实现渐进式的智能搜索。
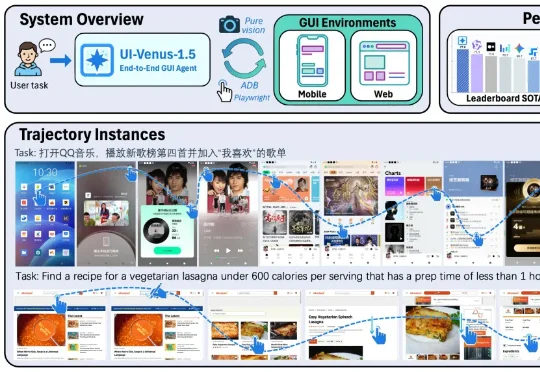
GUI 智能体最近卷到什么程度了?Claude、OpenAI Agent 及各类开源模型你方唱罢我登场,但若真想让 AI 成为 「能在手机和网页上稳定干活的助手」,仍绕不开三大现实难题:

极佳视界具身大模型 GigaBrain-0.5M*,以世界模型预测未来状态驱动机器人决策,并实现了持续自我进化,超越π*0.6 实现 SOTA!该模型在叠衣、冲咖啡、折纸盒等真实任务中实现接近 100% 成功率;相比主流基线方法任务成功率提升近 30%;基于超万小时数据训练,其中六成由自研世界模型高保真合成。

清华大学团队推出的Dolphin模型突破了「高性能必高能耗」的瓶颈:仅用6M参数(较主流模型减半),通过离散化视觉编码和物理启发的热扩散注意力机制,实现单次推理即可精准分离语音,速度提升6倍以上,在多项基准测试中刷新纪录,为智能助听器、手机等端侧设备部署高清语音分离开辟新路。