
飞猪创始人的百亿AI局:旅游版“龙虾”如何让旅行社人效翻倍增长?|甲子光年
飞猪创始人的百亿AI局:旅游版“龙虾”如何让旅行社人效翻倍增长?|甲子光年近日,国内旅游AI企业视旅科技正式上线旅游行业专属AI智能工具——VtripClaw(旅游版“龙虾”)。和OpenClaw类似,这款旅游版“龙虾”具备极强的任务拆解与自动化执行能力,并且更加适配旅游场景。
来自主题: AI资讯
9591 点击 2026-04-06 08:58
 搜索
搜索
近日,国内旅游AI企业视旅科技正式上线旅游行业专属AI智能工具——VtripClaw(旅游版“龙虾”)。和OpenClaw类似,这款旅游版“龙虾”具备极强的任务拆解与自动化执行能力,并且更加适配旅游场景。
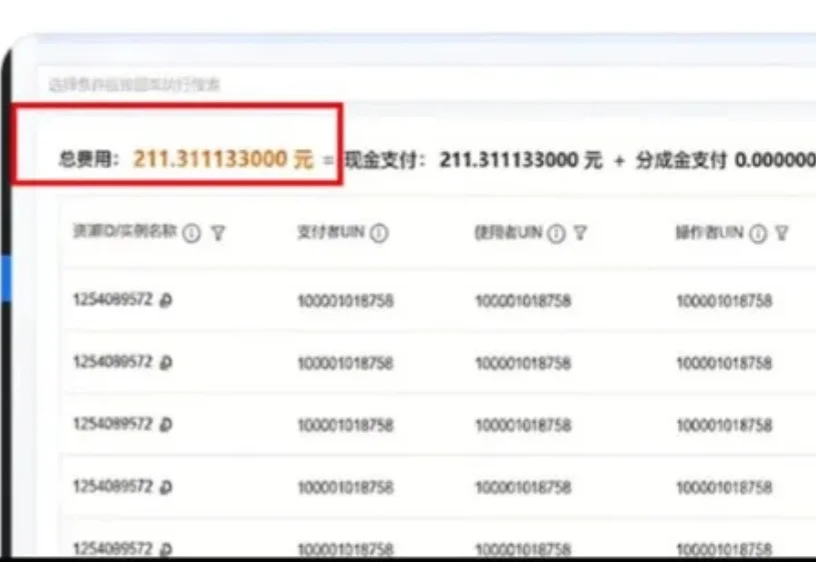
最近想必不少人都装上了「龙虾」,还没真的干什么活,先收到了一张账单。
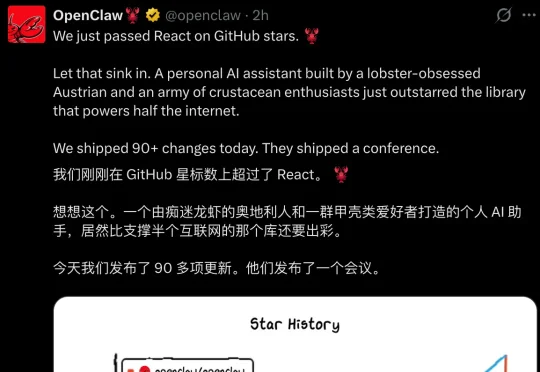
OpenClaw 最近火到什么程度?火到衍生出一门上门安装的生意。 海外代装平台 SetupClaw 已经给出明码标价:托管安装,3000 美元;含 Mac mini 硬件的远程配置,5000 美元;
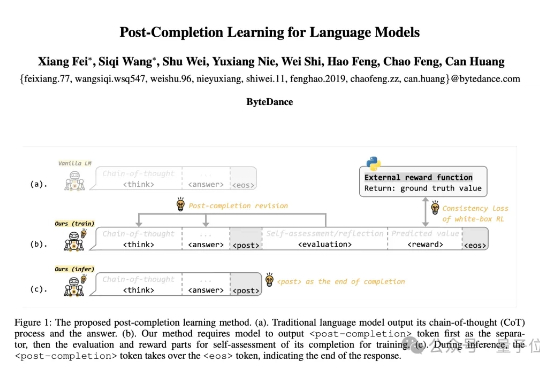
首次实现“训练-推理不对称”,字节团队提出全新的语言模型训练方法:Post-Completion Learning (PCL)。 在训练时让模型对自己的输出结果进行反思和评估,推理时却仅输出答案,将反思能力完全内化。
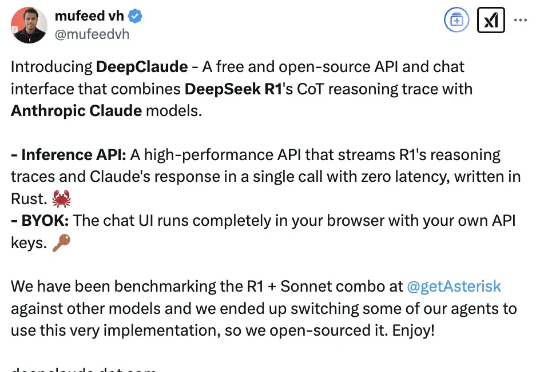
让DeepSeek代替Claude思考,缝合怪玩法火了。原因无它:比单独使用DeepSeek R1、Claude Sonnet 3.5、OpenAI o1模型的效果更好。DeepClaude应用本身100%免费且开源,在GitHub上已揽获3k星星(当然API要用自己的)。