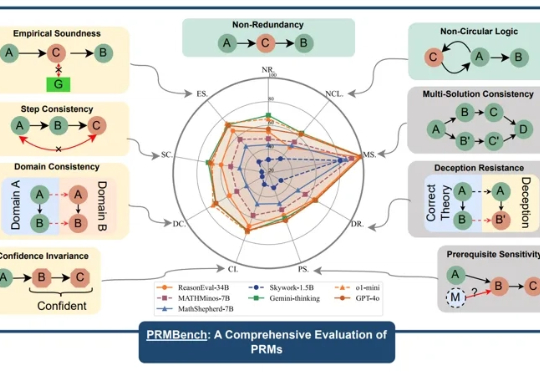
ACL 2025|驱动LLM强大的过程级奖励模型(PRMs)正遭遇「信任危机」?
ACL 2025|驱动LLM强大的过程级奖励模型(PRMs)正遭遇「信任危机」?近年来,大型语言模型(LLMs)在复杂推理任务中展现出惊人的能力,这在很大程度上得益于过程级奖励模型(PRMs)的赋能。PRMs 作为 LLMs 进行多步推理和决策的关键「幕后功臣」,负责评估推理过程的每一步,以引导模型的学习方向。
来自主题: AI技术研报
8557 点击 2025-07-28 10:49
 搜索
搜索
近年来,大型语言模型(LLMs)在复杂推理任务中展现出惊人的能力,这在很大程度上得益于过程级奖励模型(PRMs)的赋能。PRMs 作为 LLMs 进行多步推理和决策的关键「幕后功臣」,负责评估推理过程的每一步,以引导模型的学习方向。