1.5B推理模型新SOTA,RL训练新解法打破「简单题过拟合、难题学不动」的魔咒
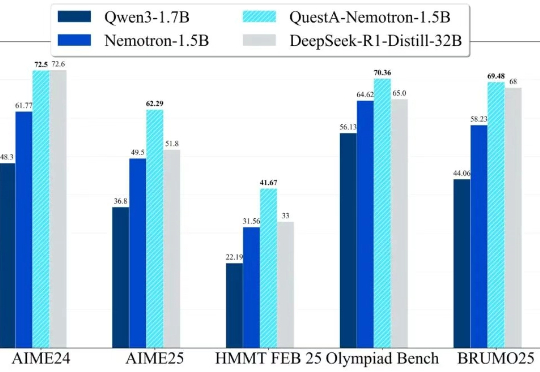
1.5B推理模型新SOTA,RL训练新解法打破「简单题过拟合、难题学不动」的魔咒QuestA(问题增强)引入了一种方法,用于提升强化学习中的推理能力。通过在训练过程中注入部分解题提示,QuestA 实现两项重大成果
来自主题: AI技术研报
9282 点击 2025-10-06 13:54
 搜索
搜索
QuestA(问题增强)引入了一种方法,用于提升强化学习中的推理能力。通过在训练过程中注入部分解题提示,QuestA 实现两项重大成果