阿里旗舰推理模型硬刚DeepSeek!官宣独立APP,发布公告AI亲自写
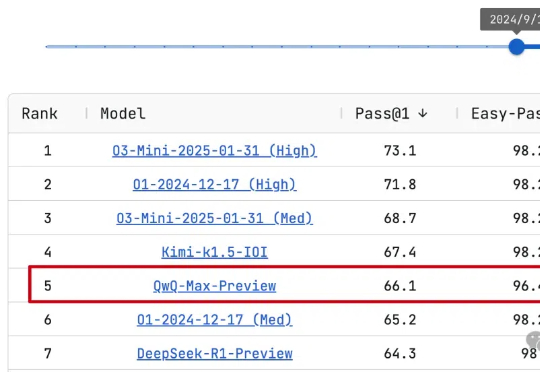
阿里旗舰推理模型硬刚DeepSeek!官宣独立APP,发布公告AI亲自写阿里通义Qwen团队熬夜通宵,推理模型Max旗舰版来了!QwQ-Max-Preview预览版,已在LiveCodeBench编程测试中排名第5,小超o1中档推理和DeepSeek-R1-Preview预览版。
来自主题: AI资讯
10007 点击 2025-02-25 11:52
 搜索
搜索
阿里通义Qwen团队熬夜通宵,推理模型Max旗舰版来了!QwQ-Max-Preview预览版,已在LiveCodeBench编程测试中排名第5,小超o1中档推理和DeepSeek-R1-Preview预览版。

推理大语言模型(LLM),如 OpenAI 的 o1 系列、Google 的 Gemini、DeepSeek 和 Qwen-QwQ 等,通过模拟人类推理过程,在多个专业领域已超越人类专家,并通过延长推理时间提高准确性。推理模型的核心技术包括强化学习(Reinforcement Learning)和推理规模(Inference scaling)。
「慢思考」(Slow-Thinking),也被称为测试时扩展(Test-Time Scaling),成为提升 LLM 推理能力的新方向。近年来,OpenAI 的 o1 [4]、DeepSeek 的 R1 [5] 以及 Qwen 的 QwQ [6] 等顶尖推理大模型的发布,进一步印证了推理过程的扩展是优化 LLM 逻辑能力的有效路径。
对于 LLM,推理时 scaling 是有效的!这一点已经被近期的许多推理大模型证明:o1、o3、DeepSeek R1、QwQ、Step Reasoner mini……

QwQ 具有神奇的推理能力。 一个刚发布两天的开源模型,正在 AI 数学奥林匹克竞赛 AIMO 上创造新纪录。