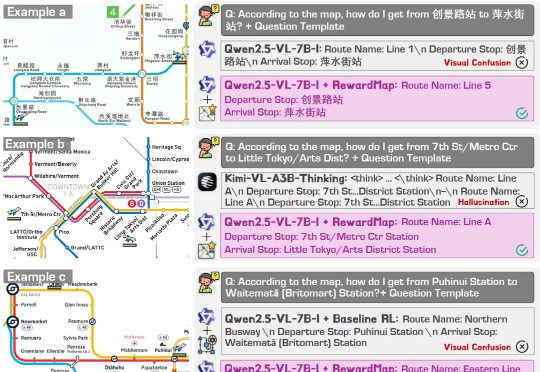
RewardMap: 通过多阶段强化学习解决细粒度视觉推理的Sparse Reward
RewardMap: 通过多阶段强化学习解决细粒度视觉推理的Sparse Reward近年来,大语言模型(LLMs)以及多模态大模型(MLLMs)在多种场景理解和复杂推理任务中取得突破性进展。
来自主题: AI技术研报
7420 点击 2025-10-21 15:53
 搜索
搜索
近年来,大语言模型(LLMs)以及多模态大模型(MLLMs)在多种场景理解和复杂推理任务中取得突破性进展。

近日,全球网络通信顶会 ACM SIGCOMM 2025 在葡萄牙落幕,共 3 篇论文获奖,华为网络技术实验室与香港科技大学 iSING Lab 合作的 DCP 研究成果,获本届大会 Best Student Paper Award (Honorable Mention),成为亚洲地域唯一获奖的论文。

DeepSeek开源周,今日正式收官!内容依旧惊喜且重磅,直接公开了V3和R1训练推理过程中用到的文件系统。Fire-Flyer文件系统(简称3FS,第三个F代表File),一种利用现代SSD和RDMA网络的全部带宽的并行文件系统;