首个为具身智能而生的大规模强化学习框架RLinf!清华、北京中关村学院、无问芯穹等重磅开源
首个为具身智能而生的大规模强化学习框架RLinf!清华、北京中关村学院、无问芯穹等重磅开源清华大学、北京中关村学院、无问芯穹联合北大、伯克利等机构重磅开源RLinf:首个面向具身智能的“渲训推一体化”大规模强化学习框架。
来自主题: AI技术研报
7627 点击 2025-09-01 16:49
 搜索
搜索
清华大学、北京中关村学院、无问芯穹联合北大、伯克利等机构重磅开源RLinf:首个面向具身智能的“渲训推一体化”大规模强化学习框架。

最近3D内容生成模型好生热闹,像谷歌Genie 3、World Labs、混元、昆仑争相发布并开测世界模型。
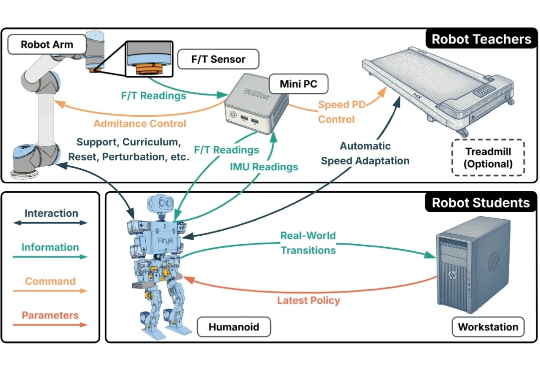
人形机器人的运动控制,正成为强化学习(RL)算法应用的下一个热点研究领域。当前,主流方案大多遵循 “仿真到现实”(Sim-to-Real)的范式。研究者们通过域随机化(Domain Randomization)技术,在成千上万个具有不同物理参数的仿真环境中训练通用控制模型,期望它能凭借强大的泛化能力,直接适应动力学特性未知的真实世界。

2023年5月,英伟达创始人黄仁勋在ITF World半导体大会上断言:“AI的下一个浪潮是具身智能。” 这一判断迅速被产业趋势所验证,从在春晚舞台上扭秧歌,到不久前机器人大会上跳舞和打拳击赛,具身智能正以前所未有的速度进入公众视野。
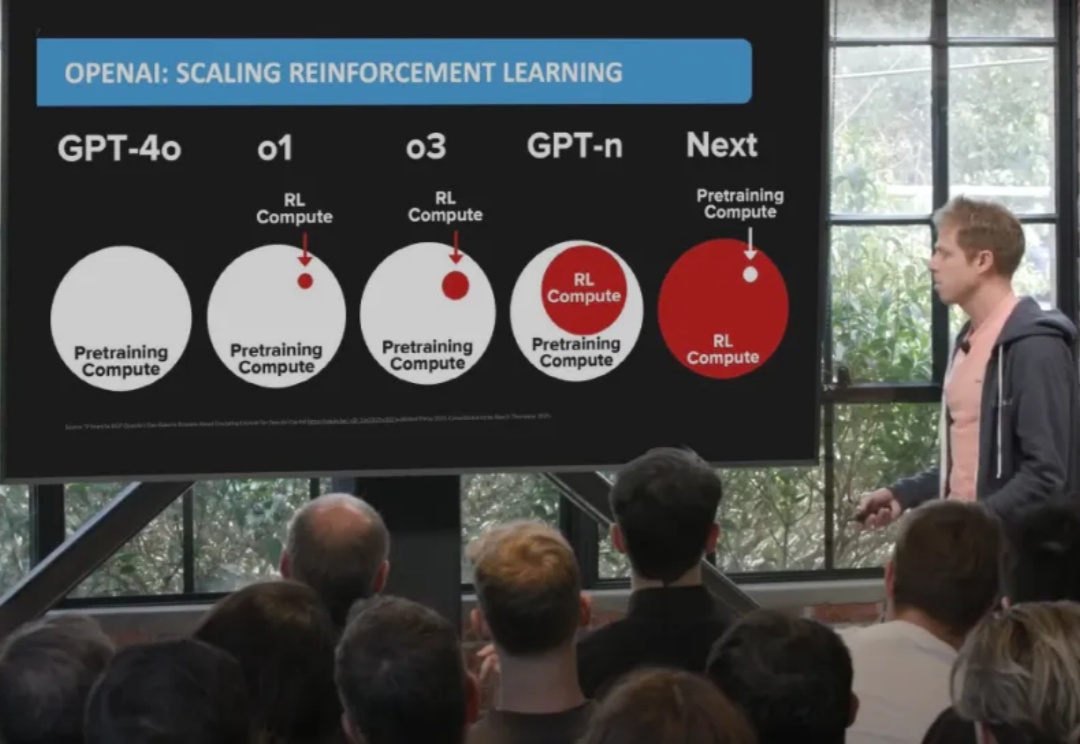
在大语言模型的竞争中,数学与代码推理能力已经成为最硬核的“分水岭”。从 OpenAI 最早将 RLHF 引入大模型训练,到 DeepSeek 提出 GRPO 算法,我们见证了强化学习在推理模型领域的巨大潜力。
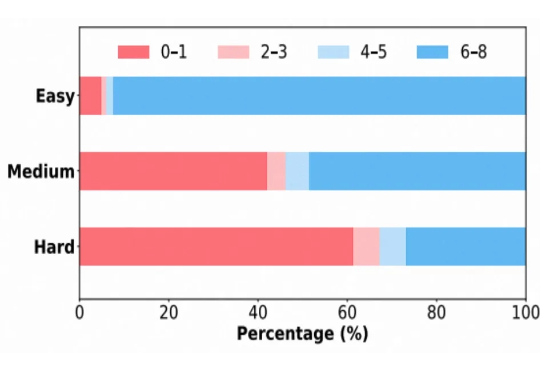
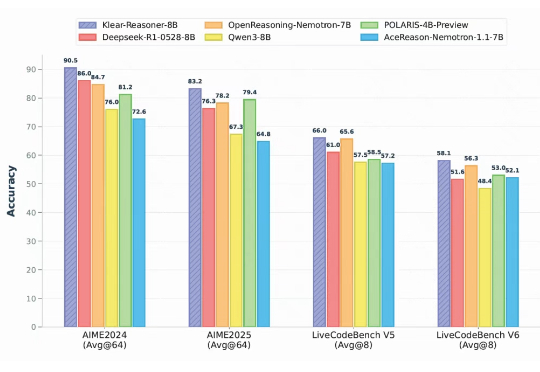
近年来,强化学习(Reinforcement Learning, RL)在提升大语言模型(LLM)复杂推理能力方面展现出显著效果,广泛应用于数学解题、代码生成等任务。通过 RL 微调的模型常在推理性能上超越仅依赖监督微调或预训练的模型。
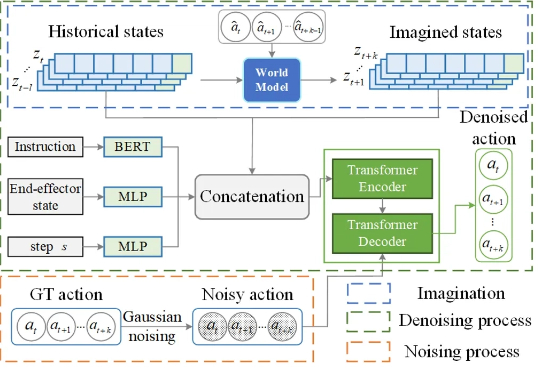
在机器人操作任务中,预测性策略近年来在具身人工智能领域引起了广泛关注,因为它能够利用预测状态来提升机器人的操作性能。然而,让世界模型预测机器人与物体交互的精确未来状态仍然是一个公认的挑战,尤其是生成高质量的像素级表示。

只需要一句话或一张图片,就能生成360度全景3D世界。
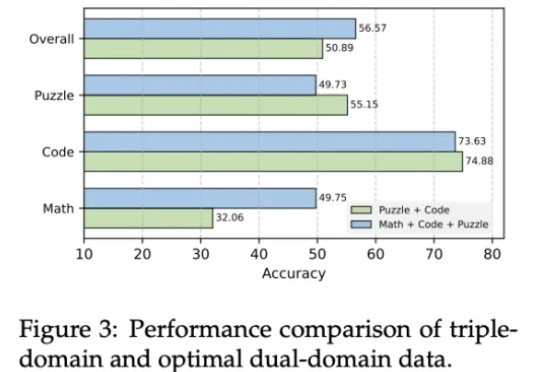
近年来,AI大模型在数学计算、逻辑推理和代码生成领域的推理能力取得了显著突破。特别是DeepSeek-R1等先进模型的出现,可验证强化学习(RLVR)技术展现出强大的性能提升潜力。

网友在推特上爆料,一位Mistral离职女员工群发邮件,直指公司多项黑幕。其中最劲爆的就是:Mistral最新模型疑似直接蒸馏自DeepSeek,却对外包装成RL成功案例,并刻意歪曲基准测试结果。