港大联手月之暗面等开源OpenCUA:人人可造专属电脑智能体
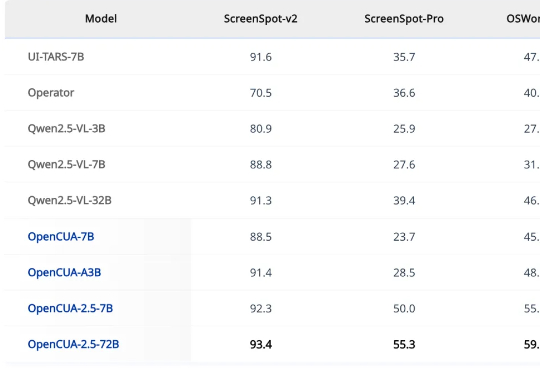
港大联手月之暗面等开源OpenCUA:人人可造专属电脑智能体刚刚,一篇来自香港大学 XLANG Lab 和月之暗面等多家机构的论文上线了 arXiv,其中提出了一个用于构建和扩展 CUA(使用计算机的智能体)的完全开源的框架。 使用该框架,他们还构建了一个旗舰模型 OpenCUA-32B,其在 OSWorld-Verified 上达到了 34.8% 的成功率,创下了新的开源 SOTA,甚至在这个基准测试中超越了 GPT-4o。
来自主题: AI技术研报
10449 点击 2025-08-14 09:39