
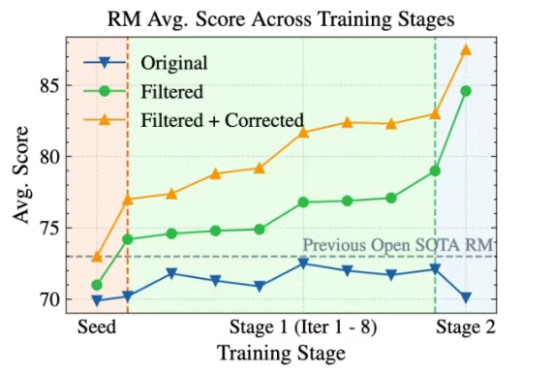
伯克利最强代码Agent屠榜SWE-Bench!用Scaling RL打造,配方全公开
伯克利最强代码Agent屠榜SWE-Bench!用Scaling RL打造,配方全公开新晋AI编程冠军DeepSWE来了!仅通过纯强化学习拿下基准测试59%的准确率,凭啥?7大算法细节首次全公开。
来自主题: AI技术研报
8844 点击 2025-07-07 15:46
 搜索
搜索
新晋AI编程冠军DeepSWE来了!仅通过纯强化学习拿下基准测试59%的准确率,凭啥?7大算法细节首次全公开。

近年来,基于智能体的强化学习(Agent + RL)与智能体优化(Agent Optimization)在学术界引发了广泛关注。然而,实现具备工具调用能力的端到端智能体训练,首要瓶颈在于高质量任务数据的极度稀缺。
大语言模型(LLM)以生成能力强而著称,但如何能让它「听话」,是一门很深的学问。 基于人类反馈的强化学习(RLHF)就是用来解决这个问题的,其中的奖励模型 (Reward Model, RM)扮演着重要的裁判作用,它专门负责给 LLM 生成的内容打分,告诉模型什么是好,什么是不好,可以保证大模型的「三观」正确。
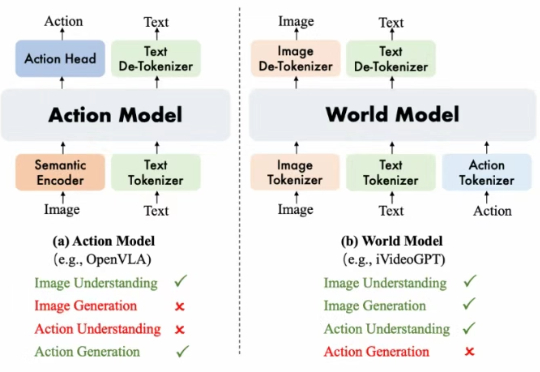
阿里巴巴达摩院提出了 WorldVLA, 首次将世界模型 (World Model) 和动作模型 (Action Model/VLA Model) 融合到了一个模型中。WorldVLA 是一个统一了文本、图片、动作理解和生成的全自回归模型。
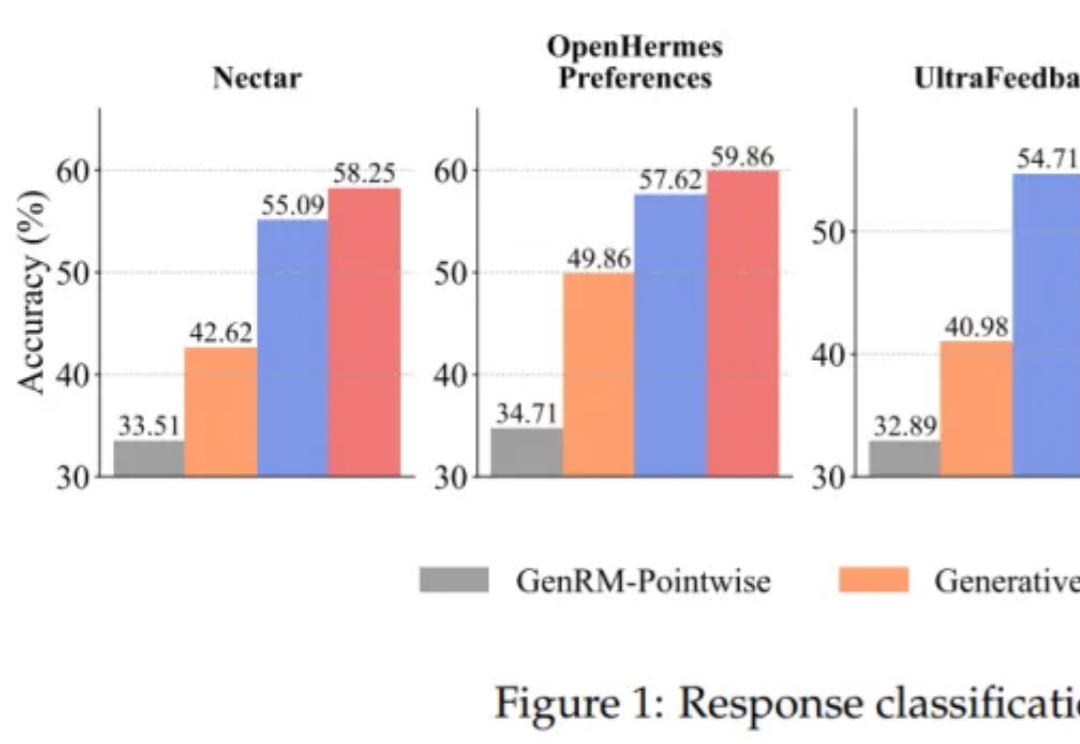
将大语言模型(LLMs)与复杂的人类价值观对齐,仍然是 AI 面临的一个核心挑战。当前主要的方法是基于人类反馈的强化学习(RLHF)。该流程依赖于一个通过人类偏好训练的奖励模型来对模型输出进行评分,最终对齐后的 LLM 的质量在根本上取决于该奖励模型的质量。
6 月 17 日,一款 AI 占星产品 Starla-Call the Universe 进入了 iOS 美国下载总榜前 10,当笔者以为这又是一个昙花一现的产品时,它不仅能够持续坚守榜单 Top 10 长达半个月,而且到了 6 月 24 日,另一款产品 Astra-Life Advice 也进入了美榜前 10,两款同类产品相继进入 Top 10,并双双持续在榜超 1 周的时间。
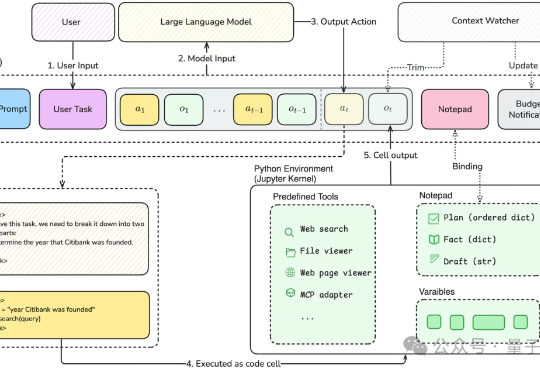
大模型可以不再依赖人类调教,真正“自学成才”啦?新研究仅通过RLVR(可验证奖励的强化学习),成功让模型自主进化出通用的探索、验证与记忆能力,让模型学会“自学”!
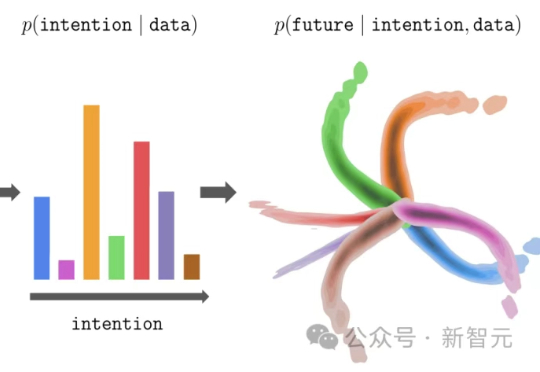
大模型的预训练-微调范式,正在悄然改写强化学习!伯克利团队提出新方法InFOM,不依赖奖励信号,也能在多个任务中实现超强迁移,还能做到「读心术」级别的推理。这到底怎么做到的?

在 AI 生成技术不断颠覆创意行业的今天,Runway 再次迈出了激动人心的一步。作为全球领先的生成式 AI 公司,Runway 长期致力于打造下一代艺术与娱乐工具。
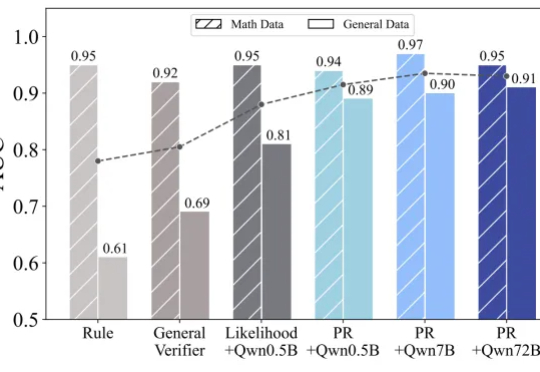
Deepseek 的 R1、OpenAI 的 o1/o3 等推理模型的出色表现充分展现了 RLVR(Reinforcement Learning with Verifiable Reward