
RL特训出「押题大师」?破解模型微调中的多样性危机与灾难性遗忘
RL特训出「押题大师」?破解模型微调中的多样性危机与灾难性遗忘RL之后,大模型为什么更容易「越训越单一」?面对五花八门的改进思路,也许答案并不复杂:先试着改一改KL项。
来自主题: AI技术研报
6089 点击 2026-04-09 14:45
 搜索
搜索
RL之后,大模型为什么更容易「越训越单一」?面对五花八门的改进思路,也许答案并不复杂:先试着改一改KL项。

今天,扣子2.5 正式上线,迎来全新升级。 一句话理解升级后的扣子:让更强大的 Claw 帮你干活,在更广阔的 Agent World 里任你探索。在过去的一段时间中,Agent 逐渐成为更多人的生产力伙伴—— 7×24 小时完成任务、自主调用工具、搞定复杂的编程,在真实的业务场景中独立完成复杂工作。
通用世界模型评测榜单 WorldScore 登顶、建立具身世界模型评测榜单 WorldArena 、发布通用世界模型 WorldScape 、发布世界-动作模型 WorldScape Policy,这家低调的世界模型创业公司 Manifold AI(流形空间)近期走出隐身模式频频出手,开始领跑世界-动作模型具身新路线。
在现实世界中通过强化学习训练智能体,往往需要大量在线试错与环境探索,这不仅成本高昂,还可能带来显著安全风险:机器人可能因试错而损坏,自动驾驶的在线探索可能危及行车安全,而持续采集交互数据本身也代价巨大。
近年来,Decision-Coupled World Model 与 Model-based RL 在机器人领域取得了显著成功。通过学习环境动力学模型,智能体能够在内部模拟未来,从而进行规划与决策。但当系统从单机器人扩展到多机器人时,问题开始变得棘手。

Anthropic 研究科学家 Nicholas Carlini 在 [un]prompted 2026 安全会议上用不到 25 分钟演示了一件事:语言模型现在可以自主找到并利用零日漏洞,目标包括 Linux 内核这种被人类安全专家审计了几十年的软件。
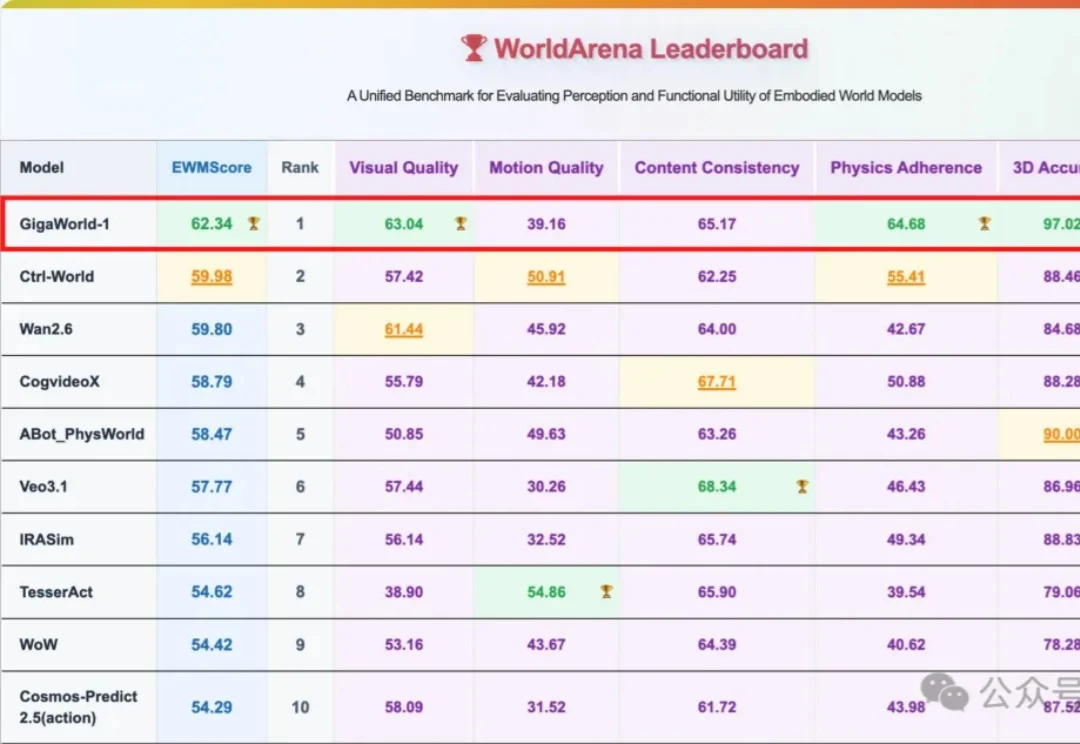
还得是咱国产世界模型牛!

在大模型后训练阶段,监督微调(SFT)和强化学习(RL)是两根不可或缺的支柱。SFT 利用高质量的离线(Off-policy)数据快速注入知识,但受限于静态数据分布,泛化能力往往容易触及天花板并带来灾难性遗忘;RL 则允许模型在探索中不断自我迭代,产生与当前策略同分布(On-policy)的数据,上限极高,但往往伴随着训练极度不稳定、计算资源消耗巨大的痛点。

近期,围绕「世界模型」这一方向,有两项工作受到较多关注。

LeCun世界模型最新进展,开源了一套极简训练方案,单GPU就能跑。