
知识储备≠模型能力!DeepMind强化学习微调:大幅缩小「知行差距」
知识储备≠模型能力!DeepMind强化学习微调:大幅缩小「知行差距」大语言模型(LLMs)在决策场景中常因贪婪性、频率偏差和知行差距表现欠佳。研究者提出强化学习微调(RLFT),通过自我生成的推理链(CoT)优化模型,提升决策能力。实验表明,RLFT可增加模型探索性,缩小知行差距,但探索策略仍有改进空间。
来自主题: AI技术研报
8361 点击 2025-06-22 11:34
 搜索
搜索
大语言模型(LLMs)在决策场景中常因贪婪性、频率偏差和知行差距表现欠佳。研究者提出强化学习微调(RLFT),通过自我生成的推理链(CoT)优化模型,提升决策能力。实验表明,RLFT可增加模型探索性,缩小知行差距,但探索策略仍有改进空间。
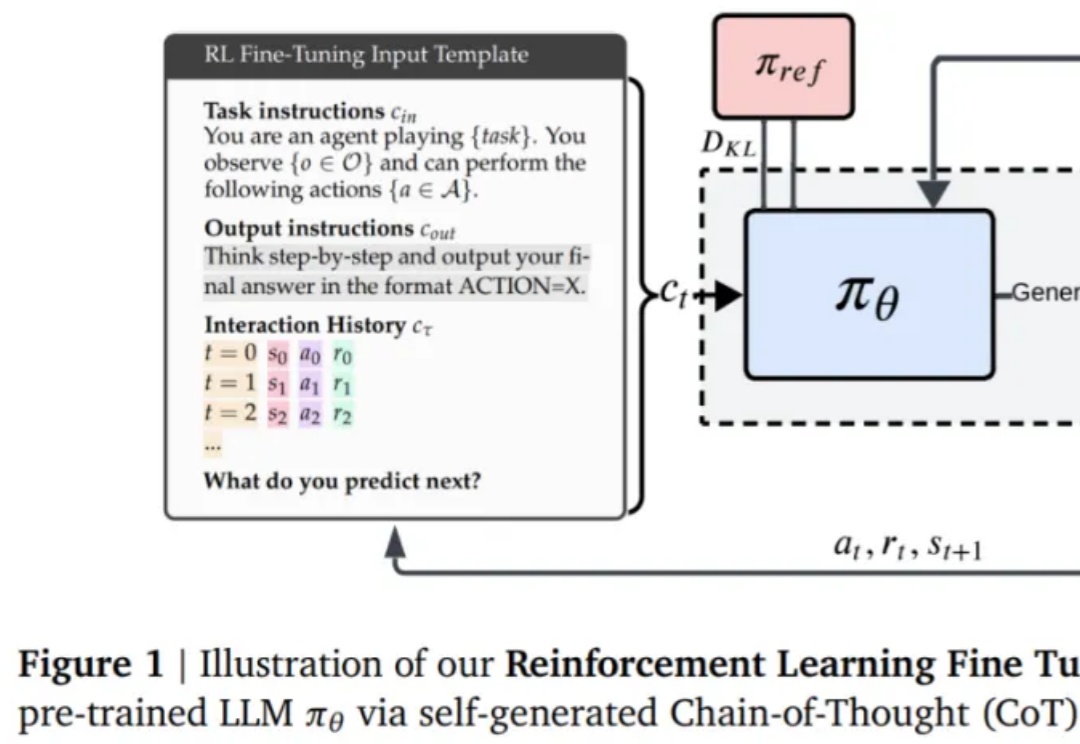
该研究对 LLM 常见的失败模式贪婪性、频率偏差和知 - 行差距,进行了深入研究。