7B模型“情商”比肩GPT-4o,腾讯突破开放域RL难题,得分直翻5倍
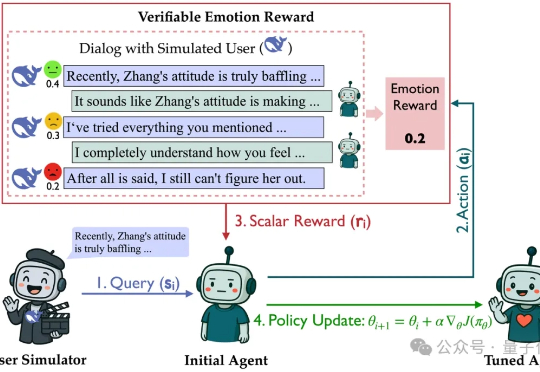
7B模型“情商”比肩GPT-4o,腾讯突破开放域RL难题,得分直翻5倍在没有标准答案的开放式对话中,RL该怎么做?多轮对话是大模型最典型的开放任务:高频、多轮、强情境依赖,且“好回复”因人而异。
来自主题: AI技术研报
8480 点击 2025-07-19 11:13
 搜索
搜索
在没有标准答案的开放式对话中,RL该怎么做?多轮对话是大模型最典型的开放任务:高频、多轮、强情境依赖,且“好回复”因人而异。