
腾讯混元最新开源:一套RL框架打通多个模态,庞天宇团队新作
腾讯混元最新开源:一套RL框架打通多个模态,庞天宇团队新作大语言模型的RL技术已日趋成熟,多模态生成模型的强化学习训练却仍在“各自为战”——图像扩散模型一套流程、视频生成另一套标准、VLM和LLM又有不同的技术栈。
来自主题: AI技术研报
7208 点击 2026-06-18 11:25
 搜索
搜索
大语言模型的RL技术已日趋成熟,多模态生成模型的强化学习训练却仍在“各自为战”——图像扩散模型一套流程、视频生成另一套标准、VLM和LLM又有不同的技术栈。
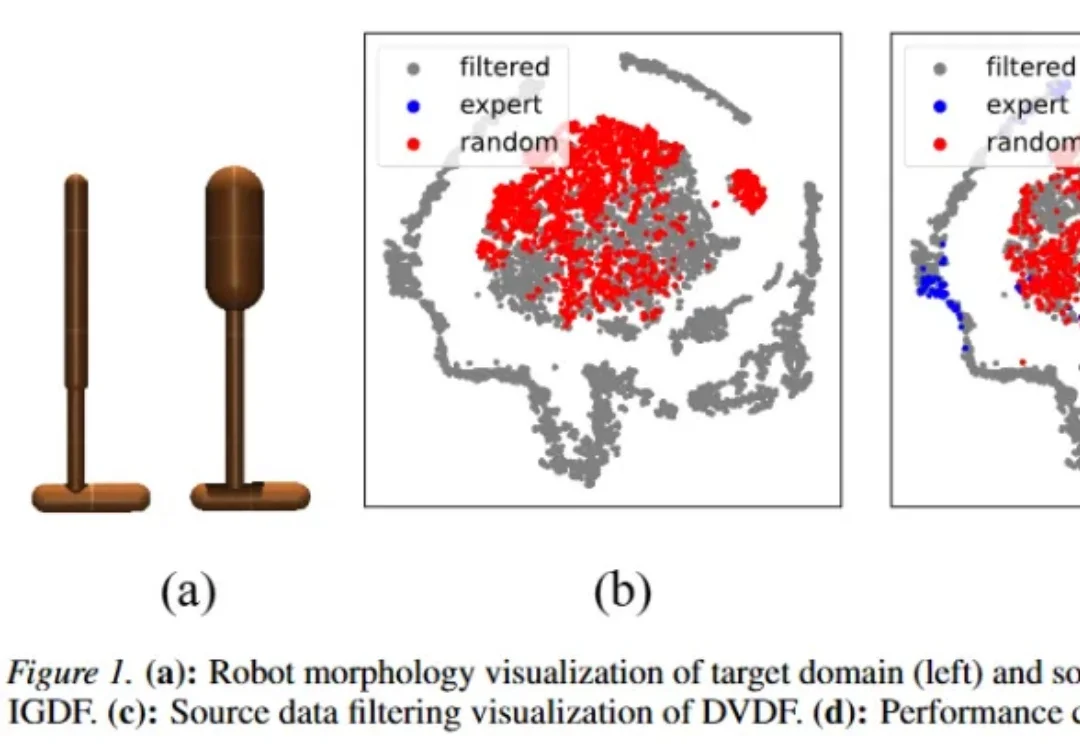
在现实世界中通过强化学习训练智能体,往往需要大量在线试错与环境探索,这不仅成本高昂,还可能带来显著安全风险:机器人可能因试错而损坏,自动驾驶的在线探索可能危及行车安全,而持续采集交互数据本身也代价巨大。

过去一周全网都在养那只红色卡通龙虾 OpenClaw。作为能够自己动手干活的 AI 智能体,有人花几千块请它回家,几天后账号被盗、文件被删,又花几百块请人卸载。从排队安装到扎堆卸载只隔了一周。

在文化遗产与人工智能的交叉处,有一类问题既美也难:如何让机器「看懂」古希腊的陶器——不仅能识别它的形状或图案,还能推断年代、产地、工坊甚至艺术归属?有研究人员给出了一条实用且富有启发性的答案:把大型多模态模型(MLLM)放在「诊断—补弱—精细化评估」的闭环中训练,并配套一个结构化的评测基准,从而让模型在高度专业化的文化遗产领域表现得更接近专家级能力。
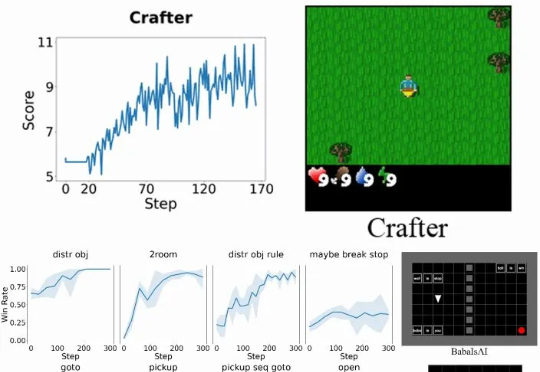
具体而言,Verlog 是一个多轮强化学习框架,专为具有高度可变回合(episode)长度的长时程(long-horizon) LLM-Agent 任务而设计。它在继承 VeRL 和 BALROG 的基础上,并遵循 pytorch-a2c-ppo-acktr-gail 的成熟设计原则,引入了一系列专门优化手段,从而在任务跨度从短暂交互到数百回合时,依然能够实现稳定而高效的训练。
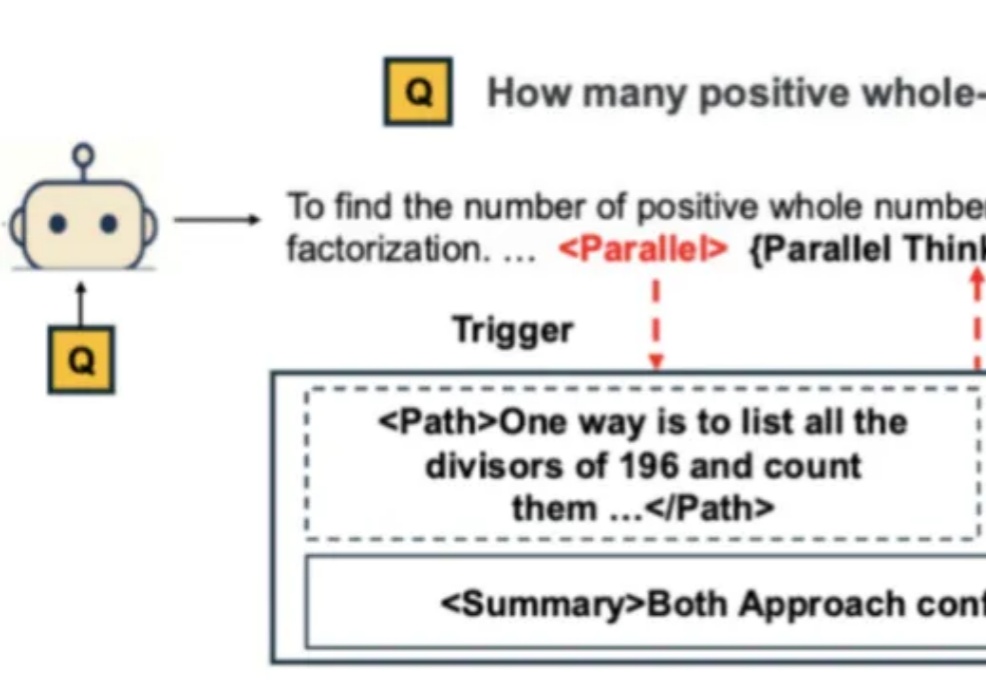
自从 Google Gemini 将数学奥赛的成功部分归功于「并行思维」后,如何让大模型掌握这种并行探索多种推理路径的能力,成为了学界关注的焦点。

强化学习(RL)范式虽然显著提升了大语言模型(LLM)在复杂任务中的表现,但其在实际应用中仍面临传统RL框架下固有的探索难题。
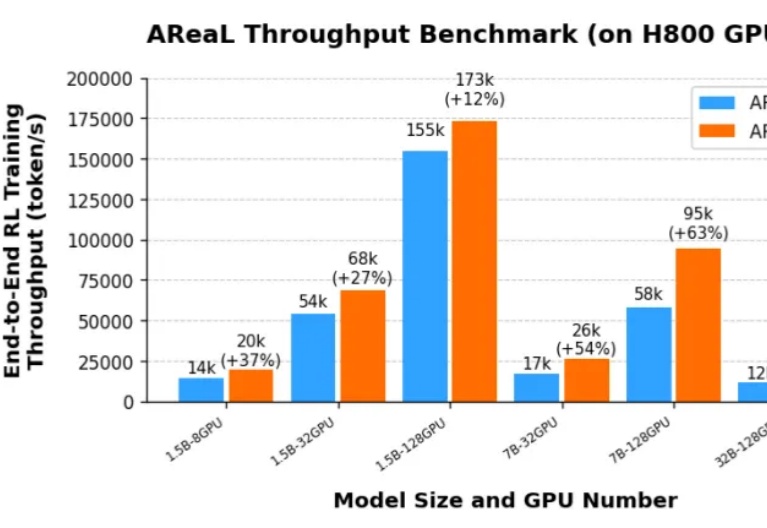
由于 DeepSeek R1 和 OpenAI o1 等推理模型(LRM,Large Reasoning Model)带来了新的 post-training scaling law,强化学习(RL,Reinforcement Learning)成为了大语言模型能力提升的新引擎。然而,针对大语言模型的大规模强化学习训练门槛一直很高:

o1 作为 OpenAI 在推理领域的最新模型,大幅度提升了 GPT-4o 在推理任务上的表现,甚至超过了平均人类水平。o1 背后的技术到底是什么?OpenAI 技术报告中所强调的强化学习和推断阶段的 Scaling Law 如何实现?