
Z Potentials|何嘉斌,跨界10年,打造CES爆火的AI陪伴机器人Ropet,赋予科技温暖灵魂
Z Potentials|何嘉斌,跨界10年,打造CES爆火的AI陪伴机器人Ropet,赋予科技温暖灵魂本期我们邀请到了萌友科技的 CEO 何嘉斌,一位从北京服装学院走出的产品设计师,以独特的女性视角和理工科思维,打造出“桌宠”Ropet——一款不以功能取胜、却以“无用之美”打动人心的情感陪伴机器人。
来自主题: AI资讯
10450 点击 2025-06-21 10:52
 搜索
搜索
本期我们邀请到了萌友科技的 CEO 何嘉斌,一位从北京服装学院走出的产品设计师,以独特的女性视角和理工科思维,打造出“桌宠”Ropet——一款不以功能取胜、却以“无用之美”打动人心的情感陪伴机器人。
长文本能力对语言模型(LM,Language Model)尤为重要,试想,如果 LM 可以处理无限长度的输入文本,我们可以预先把所有参考资料都喂给 LM,或许 LM 在应对人类的提问时就会变得无所不能。

据美国田纳西州孟菲斯市当地媒体报道,xAI计划在未来继续使用燃气轮机为其位于孟菲斯的“Colossus”超级计算机供电。今年1月,xAI附属公司CTC Property向田纳西州谢尔比县申请了15台燃气轮机的运营许可证,许可证将允许这些燃机从2025年6月至2030年6月持续运行。
开发者工具正在随着 AI 的快速发展而改变。因此,那些在其工作流程中更容易采用 AI 的公司正受到广泛关注。2022 年,一家名为 n8n(发音为“enay-ten”)的初创公司将其工作流自动化平台转向更加 AI 友好,该公司表示其收入增长了 5 倍,仅在过去两个月就翻了一番。
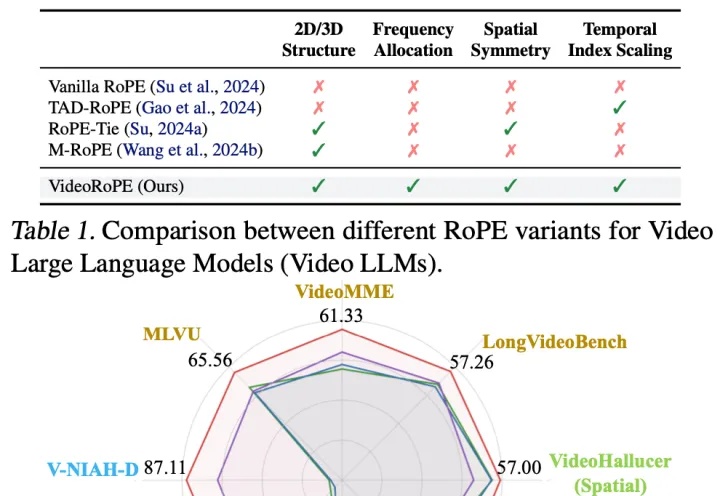
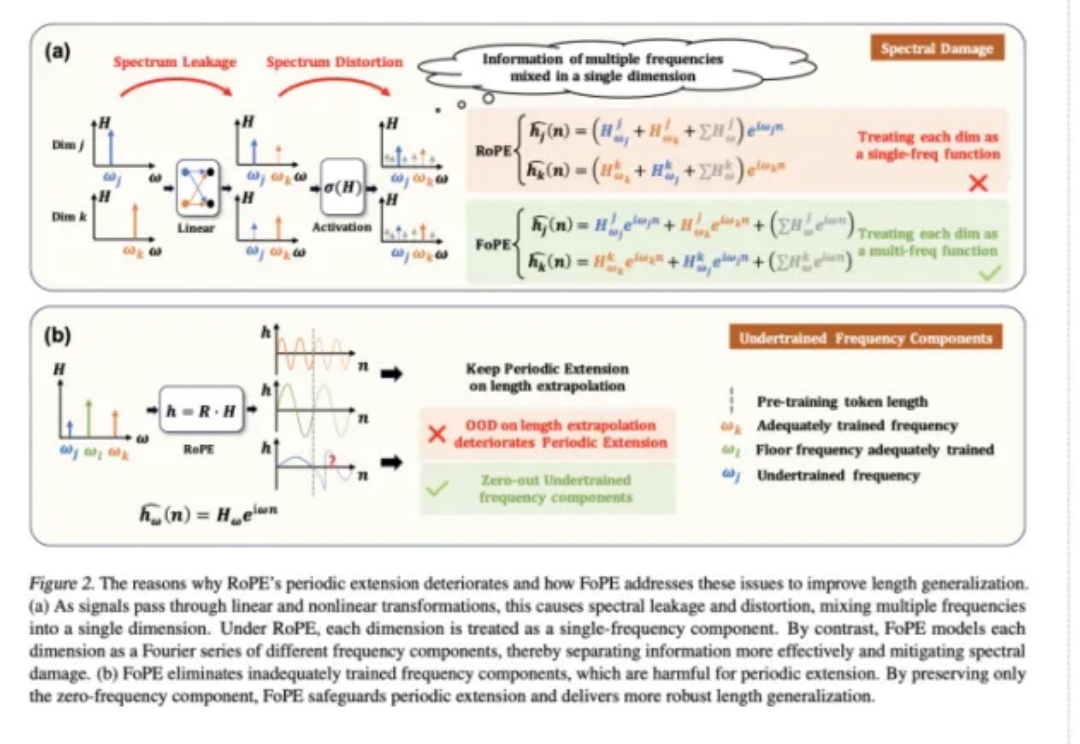
Llama都在用的RoPE(旋转位置嵌入)被扩展到视频领域,长视频理解和检索更强了。

在 CES 2025 上,我们按照惯例看到了新的显卡、笔记本电脑以及电视,但比起这些循规蹈矩的产品,一些意料之外的东西更能引发大家的兴趣。 比如一个宠物。 在 CES 2025 上,一款名为 Ropet 的新家伙引起了大家的关注。

一年一度的科技贸易展国际消费电子展 (CES) 2025年1月7日至10日在拉斯维加斯举行,预计将有超过4500家参展商,其中包括1400家初创公司。

自从 Chatgpt 诞生以来,LLM(大语言模型)的参数量似乎就成为了各个公司的竞赛指标。GPT-1 参数量为 1.17 亿(1.17M),而它的第四代 GPT-4 参数量已经刷新到了 1.8 万亿(1800B)。

当一个机器人有了名字、有了主人,一切都会变得不一样。 我拿到下面这个小玩意的时候,它告诉了我它的名字叫做Ropet,它的主人是谁,它说着它肚子饿要吃饭。

流行梗随风而过,TV Tropes 永垂不朽。