9B端侧开源模型跑通百万上下文,面壁全新稀疏-线性混合注意力架构SALA立功了!
9B端侧开源模型跑通百万上下文,面壁全新稀疏-线性混合注意力架构SALA立功了!最强的大模型,已经把scaling卷到了一个新维度:百万级上下文。
来自主题: AI技术研报
10804 点击 2026-02-12 10:35
 搜索
搜索
最强的大模型,已经把scaling卷到了一个新维度:百万级上下文。
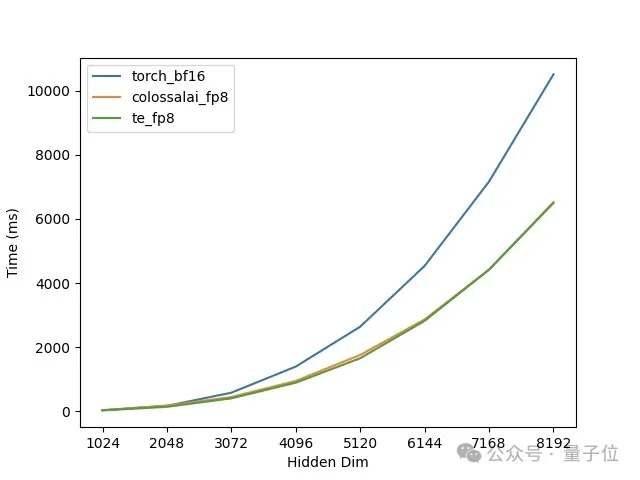
FP8通过其独特的数值表示方式,能够在保持一定精度的同时,在大模型训练中提高训练速度、节省内存占用,最终降低训练成本。