
刷榜风波惊动OpenAI后,百度伐谋(Famou)拿回Agent硬核榜单第一
刷榜风波惊动OpenAI后,百度伐谋(Famou)拿回Agent硬核榜单第一近日,在由 OpenAI 主导设立的权威基准测试 MLE-Bench 上,企业级算法自主优化智能体百度伐谋(Famou)击败了各路玩家登顶,并刷新了 SOTA 成绩。
来自主题: AI资讯
11115 点击 2026-04-11 14:24
 搜索
搜索
近日,在由 OpenAI 主导设立的权威基准测试 MLE-Bench 上,企业级算法自主优化智能体百度伐谋(Famou)击败了各路玩家登顶,并刷新了 SOTA 成绩。
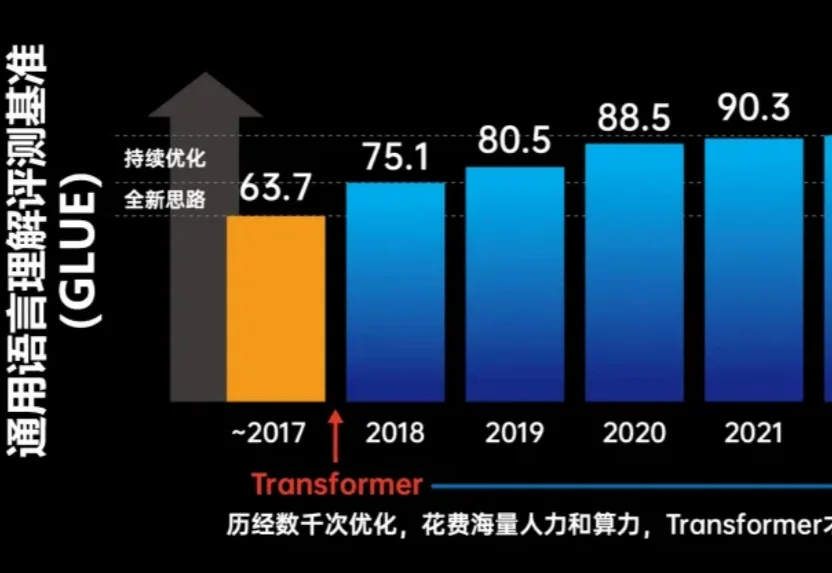
在人工智能研究中,许多研究者将大量时间投入到为那 1% 的性能提升反复调参与实验迭代之中。
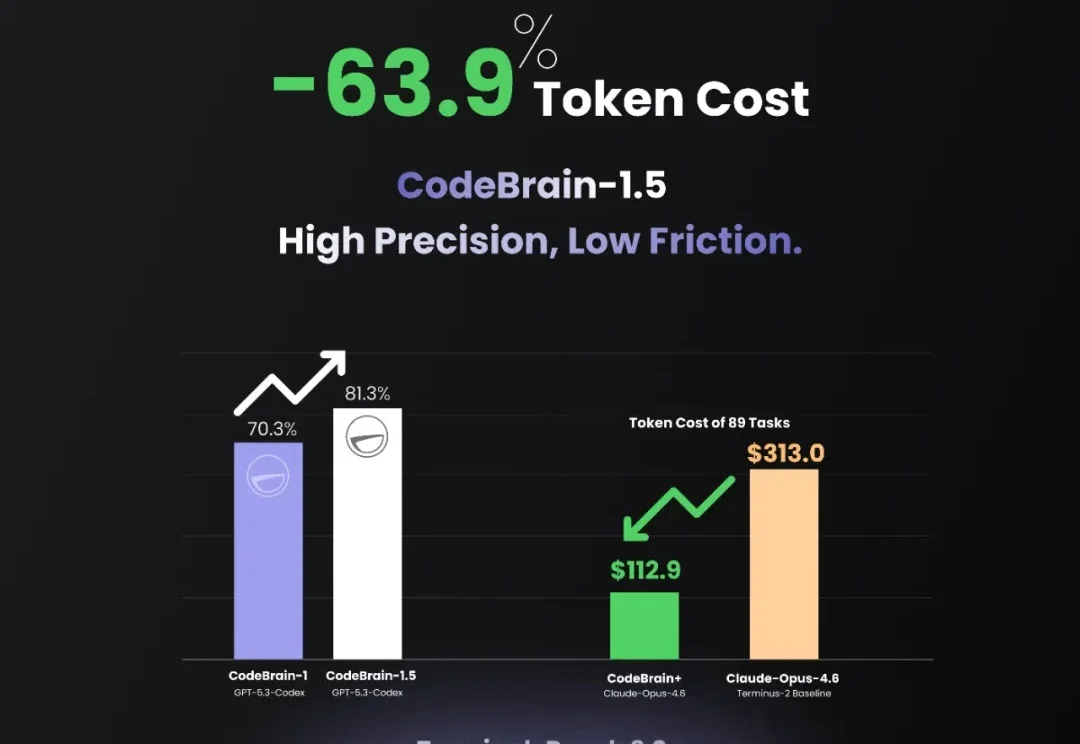
刚刚,世界模型初创公司 Feeling AI 正式发布并开源 MemBrain1.5 和 CodeBrain-1。这两项在全球 Agentic 领域的顶尖工作同时开源,将正式终结 AI “无状态” 的工具时代,为世界模型植入具备自主逻辑与层级化记忆的 “原生大脑”,开启人机深度协同的交互新范式。
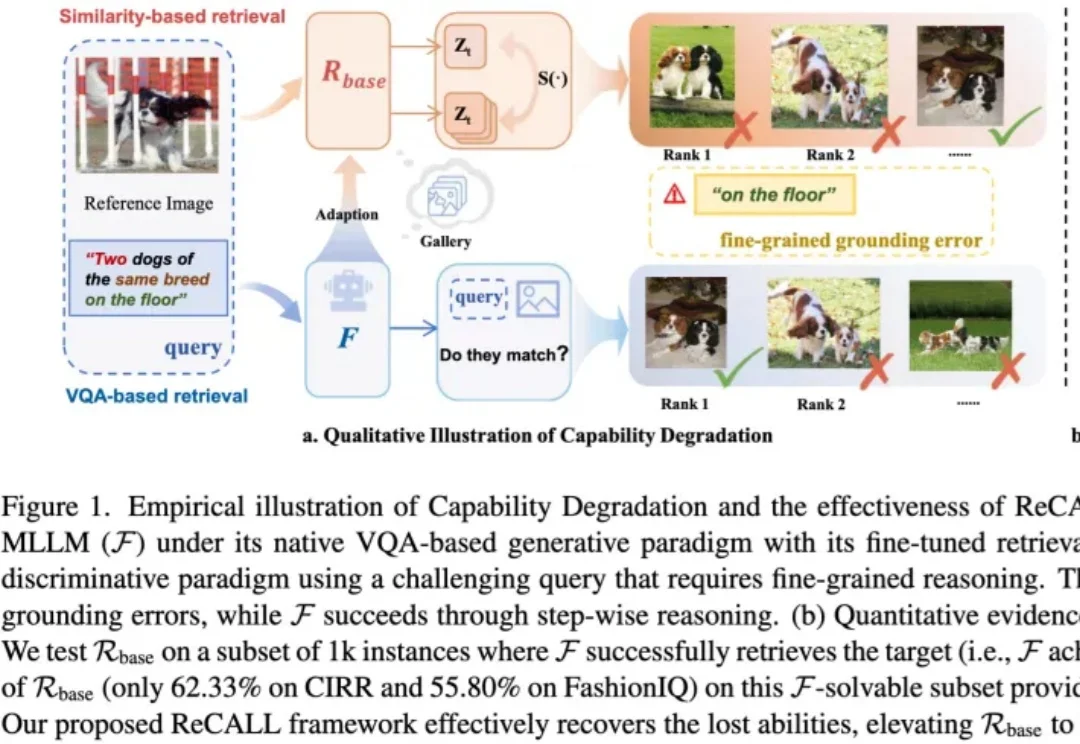
生成式模型当检索器大材小用效果还不好?

什么在限制空间智能落地?

本文综合北京大学王选计算机研究所发布的 ProactiveVideoQA 和 MMDuet2 两篇论文,介绍视频多模态大模型如何实现 “主动交互”—— 在视频播放过程中自主决定何时发起回复,而非等待用户提问。ProactiveVideoQA 提出评估指标和 benchmark,MMDuet2 则通过强化学习训练方法实现了 SOTA 性能,无需精确的回复时间标注即可训练出及时、准确的主动交互模型。

AI终于有了「永久记忆」!今天,超级记忆系统ASMR重磅登场,在业界公认最难AI记忆考试中,刷爆SOTA拿下99%成绩。全网直呼太疯狂。
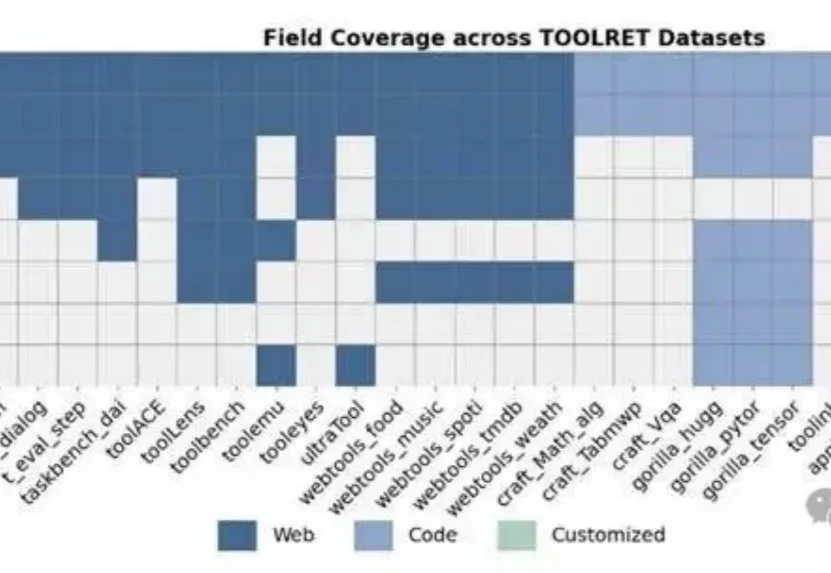
在大模型时代,Tool-Use已经成为智能体能力的核心组成部分。
打破多模态视觉+语言拼接套路!

多模态模型代码写得像老司机,却在数手指、量柱子时频频翻车?UniPat AI用五百行代码打造的SWE-Vision,让模型「掏出Python尺子」自我验证,一举拿下五大视觉相关基准SOTA。