全新线性注意力范式!哈工深张正团队提出模长感知线性注意力!显存直降92.3%!
全新线性注意力范式!哈工深张正团队提出模长感知线性注意力!显存直降92.3%!当 Transformer 席卷计算机视觉领域,高分辨率图像、超长序列任务带来的算力与显存瓶颈愈发凸显:标准 Softmax 注意力的二次复杂度,让 70K+token 的超分辨率任务直接显存爆炸,高分辨率图像分割、检测的推理延迟居高不下。
来自主题: AI技术研报
5907 点击 2026-03-17 08:48
 搜索
搜索
当 Transformer 席卷计算机视觉领域,高分辨率图像、超长序列任务带来的算力与显存瓶颈愈发凸显:标准 Softmax 注意力的二次复杂度,让 70K+token 的超分辨率任务直接显存爆炸,高分辨率图像分割、检测的推理延迟居高不下。
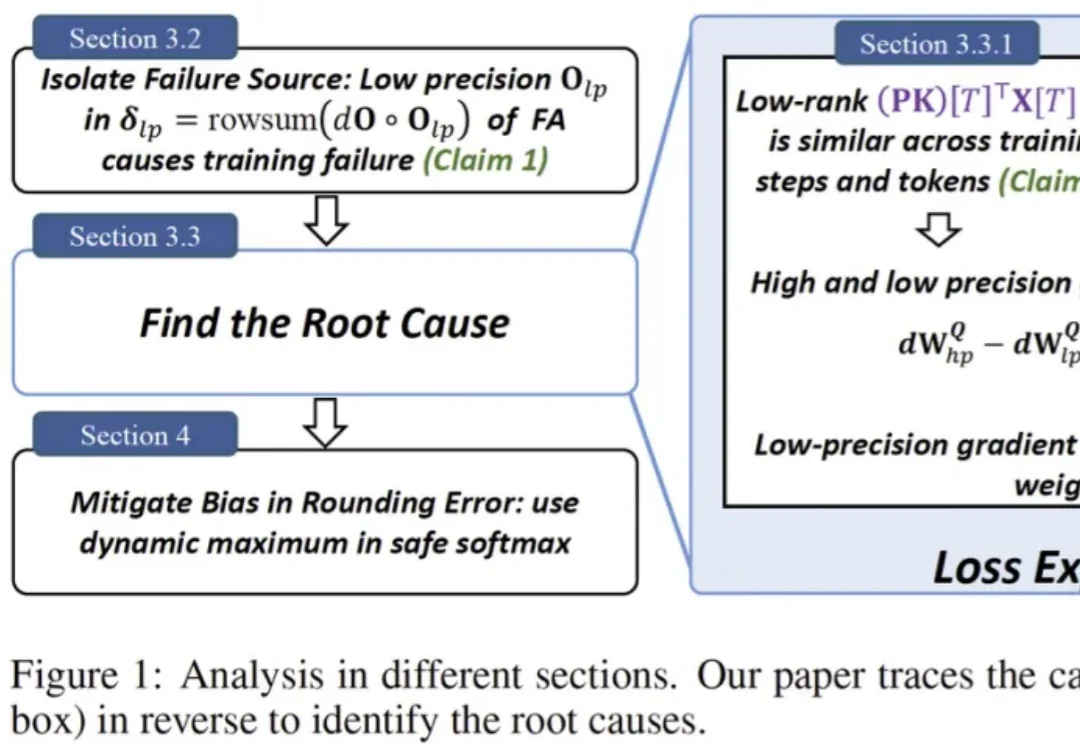
一句话总结:社区里困扰了多年的一个 “玄学” 现象终于被拆解清楚了:在 BF16 等低精度训练里,FlashAttention 不是随机出 bug,而是会在特定条件下触发有方向的数值偏置,借助注意力中涌现的相似低秩更新方向被持续放大,最终把权重谱范数和激活推到失控,导致 loss 突然爆炸。论文还给出一个几乎不改模型、只在 safe softmax 里做的极小修改,实测能显著稳定训练。
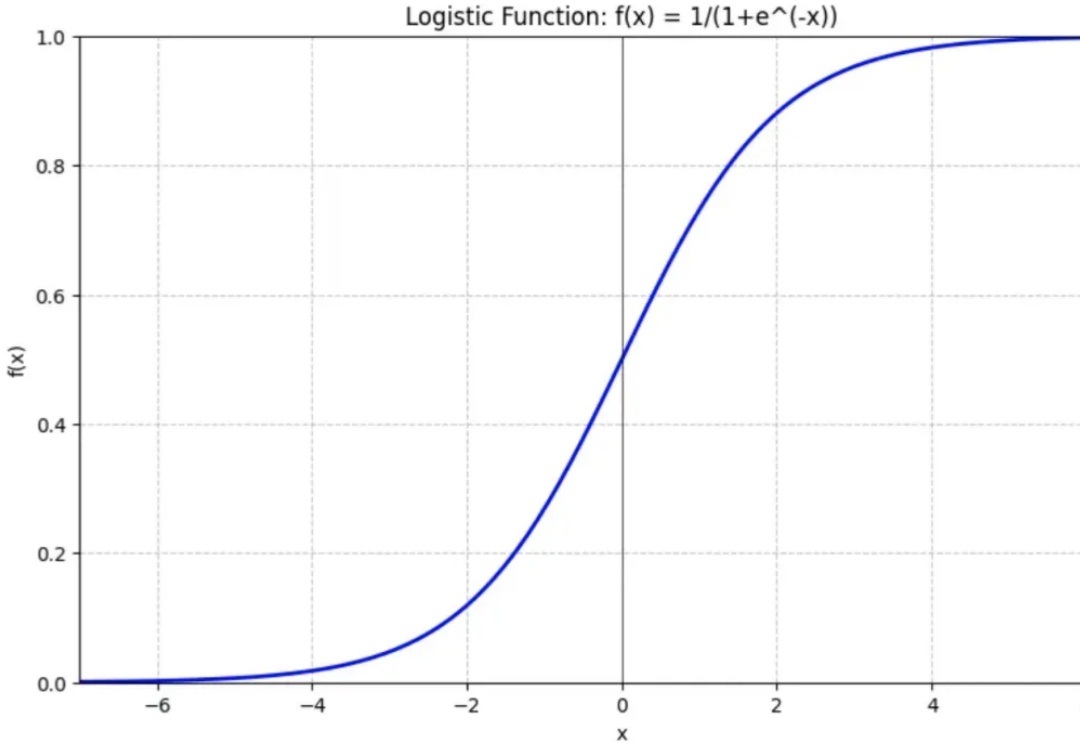
LLM本质上是一个基于概率输出的神经网络模型。但这里的“概率”来自哪里?今天我们就来说说语言模型中一个重要的角色:Softmax函数。(相信我,本文真的只需要初等函数知识)

最新综述论文探讨了知识蒸馏在持续学习中的应用,重点研究如何通过模仿旧模型的输出来减缓灾难性遗忘问题。通过在多个数据集上的实验,验证了知识蒸馏在巩固记忆方面的有效性,并指出结合数据回放和使用separated softmax损失函数可进一步提升其效果。

注意力是 Transformer 架构的关键部分,负责将每个序列元素转换为值的加权和。将查询与所有键进行点积,然后通过 softmax 函数归一化,会得到每个键对应的注意力权重。

语言建模领域的最新进展在于在极大规模的网络文本语料库上预训练高参数化的神经网络。在实践中,使用这样的模型进行训练和推断可能会成本高昂,这促使人们使用较小的替代模型。然而,已经观察到较小的模型可能会出现饱和现象,表现为在训练的某个高级阶段性能下降并趋于稳定。

来自清华大学的研究者提出了一种新的注意力范式——代理注意力 (Agent Attention)。