多模态大模型中Attention机制暗藏「骗局」,需用一个公式修正丨上大×南开
多模态大模型中Attention机制暗藏「骗局」,需用一个公式修正丨上大×南开Attention真的可靠吗?
来自主题: AI技术研报
8808 点击 2026-01-27 16:17
 搜索
搜索
Attention真的可靠吗?

刚刚,英伟达杰出工程师许冰(Bing Xu)在 GitHub 上开源了一个新项目 VibeTensor,让我们看到了 AI 在编程方面的强大实力。从名字也能看出来,这是 Vibe Coding 的成果。事实也确实如此,这位谷歌学术引用量超 20 万的工程师在 X 上表示:「这是第一个完全由 AI 智能体生成的深度学习系统,没有一行人类编写的代码。」

AI 推理基础设施公司 Baseten 近日完成一轮 3 亿美元的成长型融资,投后估值约 50 亿美元。与不到六个月前的一轮重要融资相比,公司估值几乎翻倍。 这一交易清晰地表明,在大模型训练之外,推理
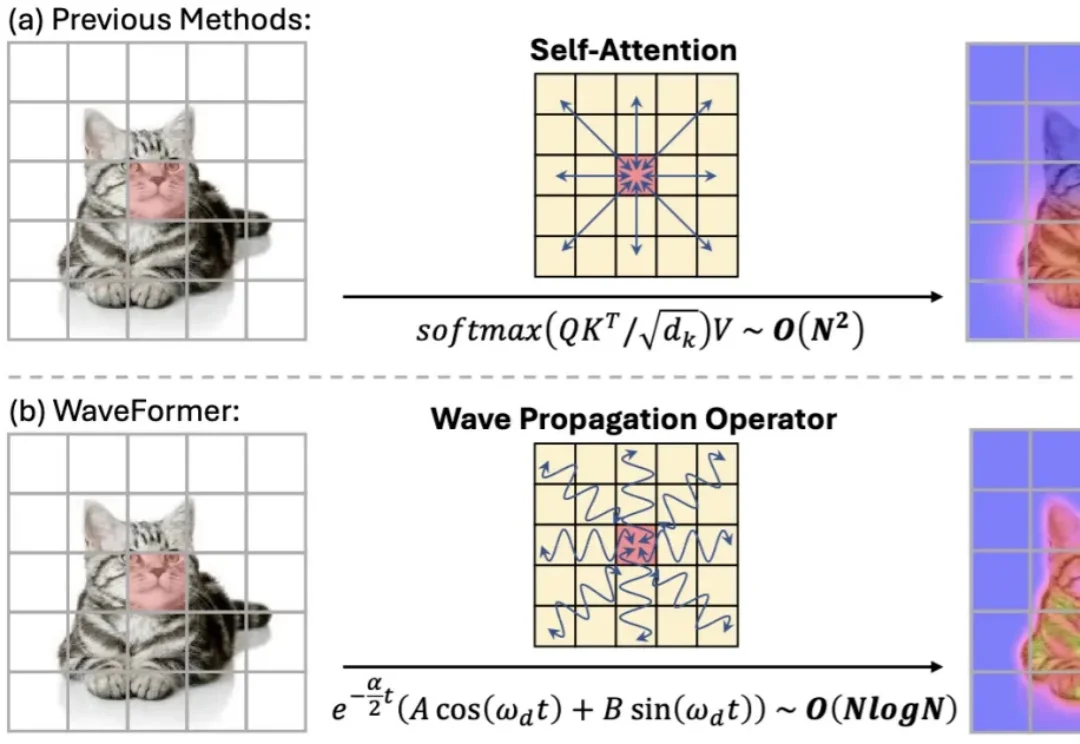
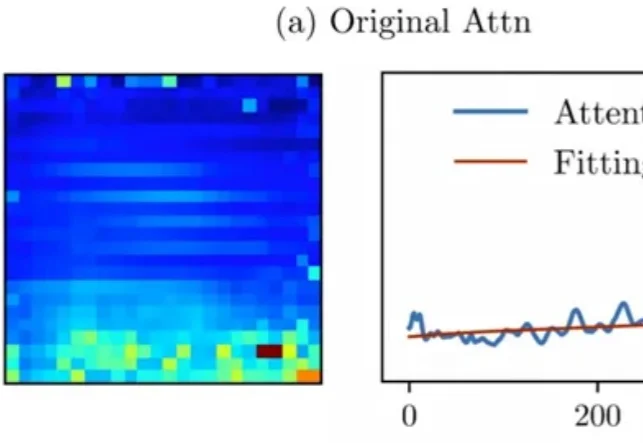
“全局交互” 几乎等同于 self-attention:每个 token 都能和所有 token 对话,效果强,但代价也直观 —— 复杂度随 token 数平方增长,分辨率一高就吃不消。现有方法大多从 “相似度匹配” 出发(attention),或从 “扩散 / 传导” 出发(热方程类方法)。但热方程本质上是一个强低通滤波器:随着传播时间增加,高频细节(边缘、纹理)会迅速消失,导致特征过平滑。
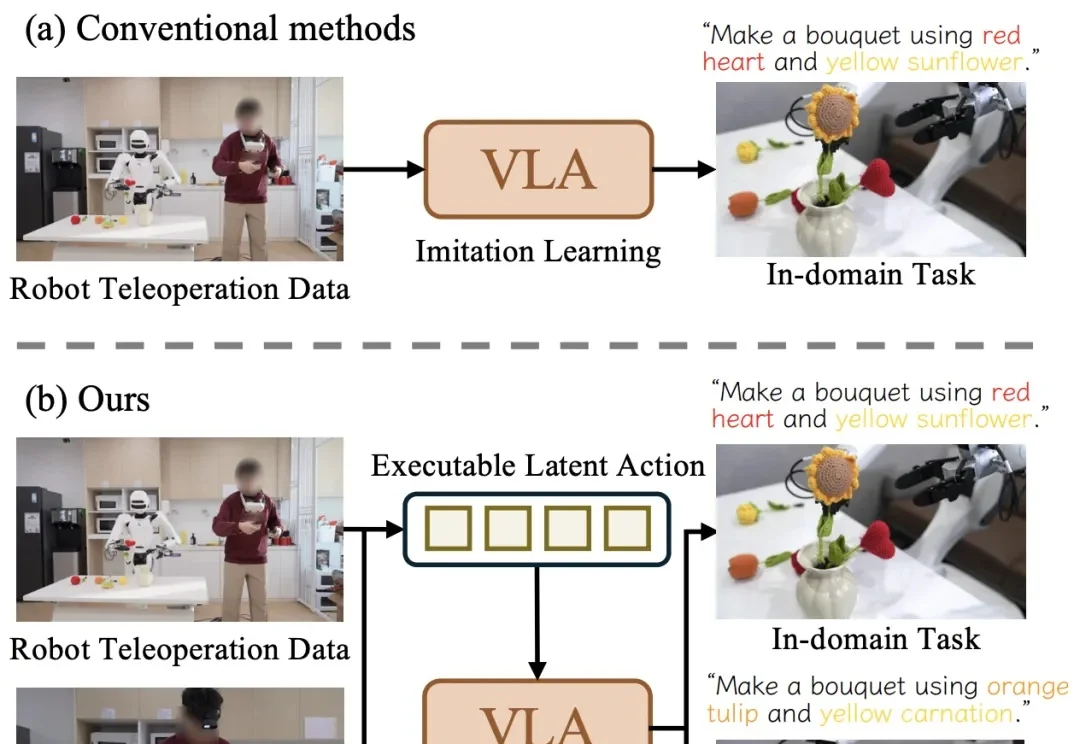
近日,清华大学与星尘智能、港大、MIT 联合提出基于对比学习的隐空间动作预训练(Contrastive Latent Action Pretraining, CLAP)框架。这个框架能够将视频中提纯的运动空间与机器人的动作空间进行对齐,也就是说,机器人能够直接从视频中学习技能!
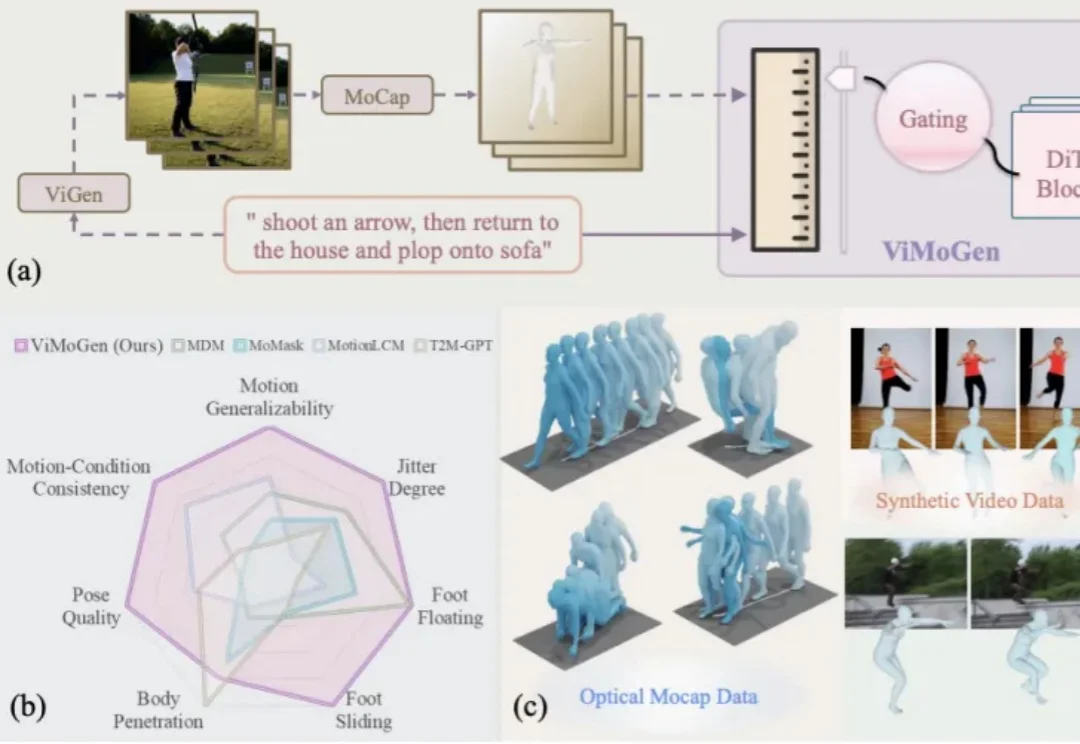
随着 AIGC(Artificial Intelligence Generated Content) 的爆发,我们已经习惯了像 Sora 或 Wan 这样的视频生成模型能够理解「一只宇航员在火星后空翻」这样天马行空的指令。然而,3D 人体动作生成(3D MoGen)领域却稍显滞后。

月前,Pollo.ai 拿下千万美元融资,而今日, ListenHub 也拿下了 200 万美元融资。两个产品都没有做自研模型,创始人也都不是典型的技术或者大厂出身,都是非典型的 AI 应用层创业,这个在 2024年“质疑”声很大的模式,在 2025 年却结出了不少的果实。
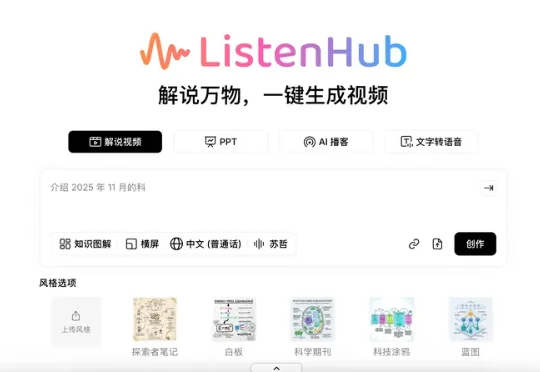
据我们独家获悉,ListenHub产品的母公司MarsWave完成了200万美元天使+轮融资。本轮由天际资本领投,小米联合创始人王川跟投。同时,MarsWave也对外公布了盈利状况:目前公司年经常性收入(ARR)已突破300万美元,并达到月度盈亏平衡,成为少数已跑通盈利模型的AI原生公司。
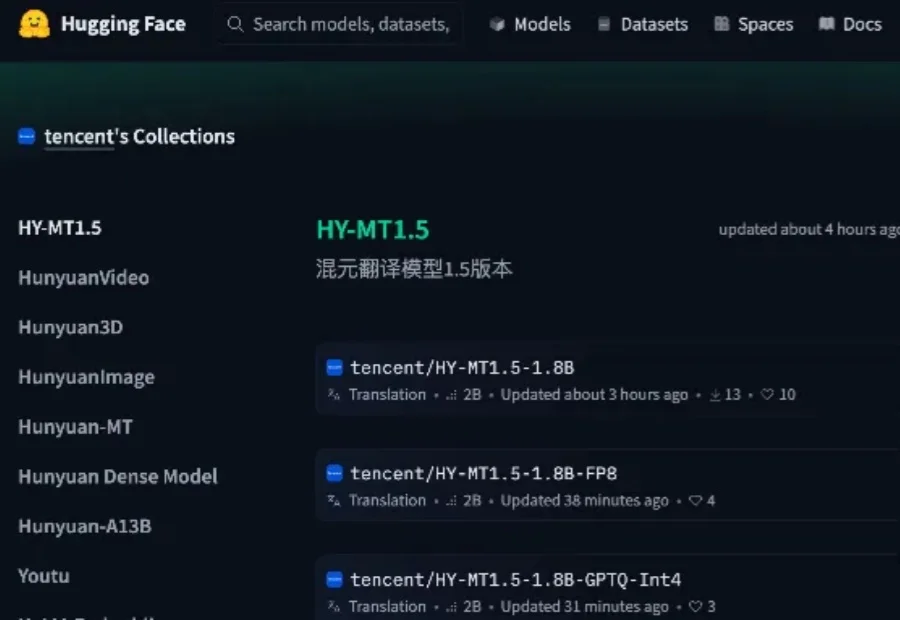
能翻译33语种+5方言,医学术语/粤语翻译实测“能打”。

Content in,Design out。