
黄仁勋最新访谈:英伟达投资OpenAI不是签署大额订单的前提
黄仁勋最新访谈:英伟达投资OpenAI不是签署大额订单的前提9月25日,在播客BG2最新一期节目中,BG2主播、Altimeter Capital创始人Brad Gerstner,Altimeter Capital合伙人Clark Tang与英伟达CEO黄仁勋展开了一次对话。黄仁勋在对话中回应了当下市场的关心的问题。
来自主题: AI资讯
8539 点击 2025-09-27 10:29
 搜索
搜索
9月25日,在播客BG2最新一期节目中,BG2主播、Altimeter Capital创始人Brad Gerstner,Altimeter Capital合伙人Clark Tang与英伟达CEO黄仁勋展开了一次对话。黄仁勋在对话中回应了当下市场的关心的问题。
“看得出 Anthropic 是真急了,都开始澄清了。”有网友在看到发文解释 8 月至 9 月初陆续出现 bug 的推文后表示。“产品质量这么差。我之前不明白为什么,现在明白了。”开发者 Tim McGuire 在帖子下表示。
马斯克在忙着裁人,小扎这边继续忙着挖人。 这不?Optimus AI团队负责人Ashish Kumar决定离开特斯拉,加入Meta担任研究科学家。与此同时,小扎砸钱挖人的形象已经深入人心,使得网友不禁锐评,有10亿美元吗?

近年来,大语言模型(LLMs)在复杂推理任务上的能力突飞猛进,这在很大程度上得益于深度思考的策略,即通过增加测试时(test-time)的计算量,让模型生成更长的思维链(Chain-of-Thought)。
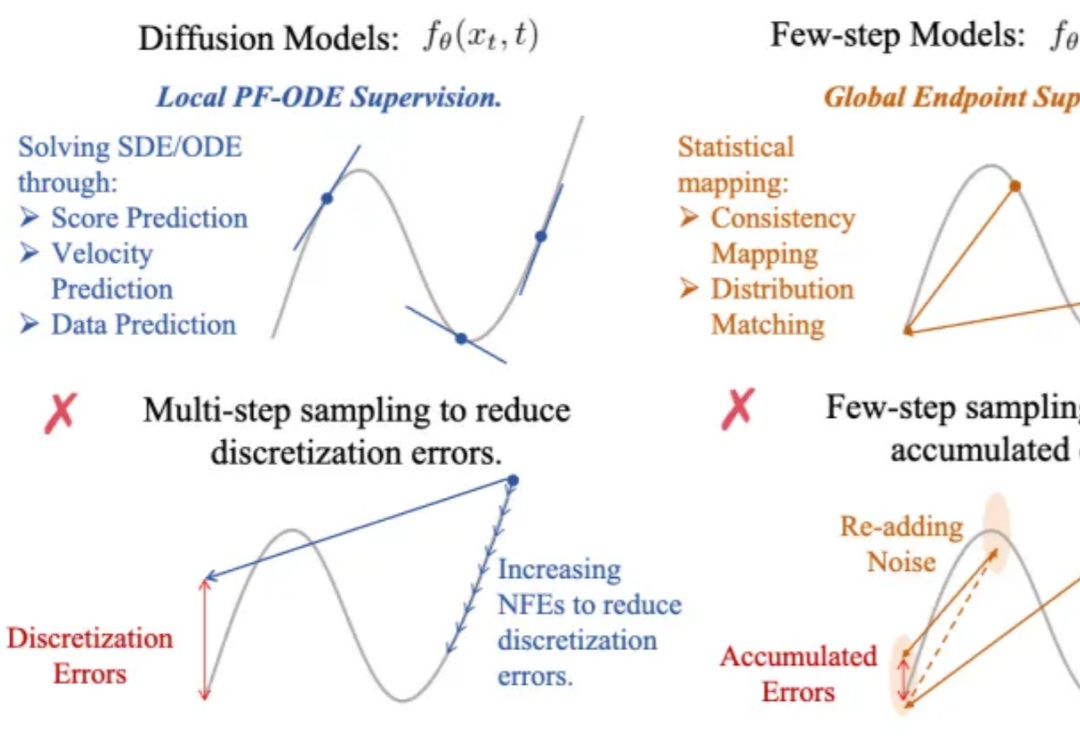
生成式AI的快与好,终于能兼得了?

自动化修复真实世界的软件缺陷问题是自动化程序修复研究社区的长期目标。然而,如何自动化解决视觉软件缺陷仍然是一个尚未充分探索的领域。最近,随着 SWE-bench 团队发布最新的多模态 Issue 修复

金色外观擎天柱首次曝出!一双与人类无异的双手震惊全网,且设计与现有第二代有所不同。网友纷纷猜测,Optimus第三代要来了。
近日,快手与清华大学孙立峰团队联合发表论文《Towards User-level QoE: Large-scale Practice in Personalized Optimization of Adaptive Video Streaming》,被计算机网络领域的国际顶尖学术会议 ACM SIGCOMM 2025 录用。
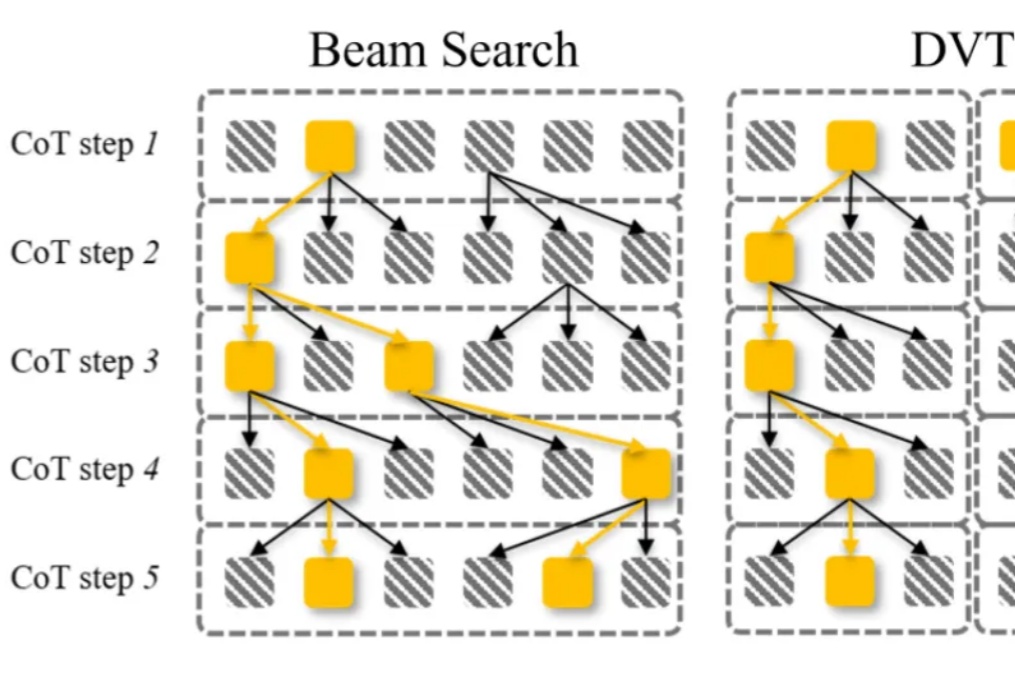
大语言模型通过 CoT 已具备强大的数学推理能力,而 Beam Search、DVTS 等测试时扩展(Test-Time Scaling, TTS)方法可通过分配额外计算资源进一步提升准确性。然而,现有方法存在两大关键缺陷:路径同质化(推理路径趋同)和中间结果利用不足(大量高质量推理分支被丢弃)。

OpenAI凌晨发布最新生产级别语音模型和API。Realtime API实现语音直接处理,支持图像输入、远程MCP服务器与SIP打电话,极大简化语音智能体构建;而新一代语音到语音模型gpt-realtime,在音质、理解力、指令遵循和函数调用上全面提升,语音几乎媲美真人,还能多语种切换与细腻表达。