
推理模型其实无需「思考」?伯克利发现有时跳过思考过程会更快、更准确
推理模型其实无需「思考」?伯克利发现有时跳过思考过程会更快、更准确当 DeepSeek-R1、OpenAI o1 这样的大型推理模型还在通过增加推理时的计算量提升性能时,加州大学伯克利分校与艾伦人工智能研究所突然扔出了一颗深水炸弹:别再卷 token 了,无需显式思维链,推理模型也能实现高效且准确的推理。
来自主题: AI技术研报
8717 点击 2025-04-19 14:39
 搜索
搜索
当 DeepSeek-R1、OpenAI o1 这样的大型推理模型还在通过增加推理时的计算量提升性能时,加州大学伯克利分校与艾伦人工智能研究所突然扔出了一颗深水炸弹:别再卷 token 了,无需显式思维链,推理模型也能实现高效且准确的推理。
今天凌晨,OpenAI 的新系列模型 GPT-4.1 如约而至。

就在刚刚,智谱一口气上线并开源了三大类最新的GLM模型:沉思模型GLM-Z1-Rumination 推理模型GLM-Z1-Air 基座模型GLM-4-Air-0414

开发Agent的工程师们都曾面临同一个棘手问题:当任务步骤增多,你的Agent就像患上"数字健忘症",忘记之前做过什么,无法处理用户的修改请求,甚至在多轮对话中迷失自我。不仅用户体验受损,token开销也居高不下。TME树状记忆引擎通过结构化状态管理方案,彻底解决了这一痛点,让你的Agent像拥有完美记忆力的助手,在复杂任务中游刃有余,同时将token消耗降低26%。
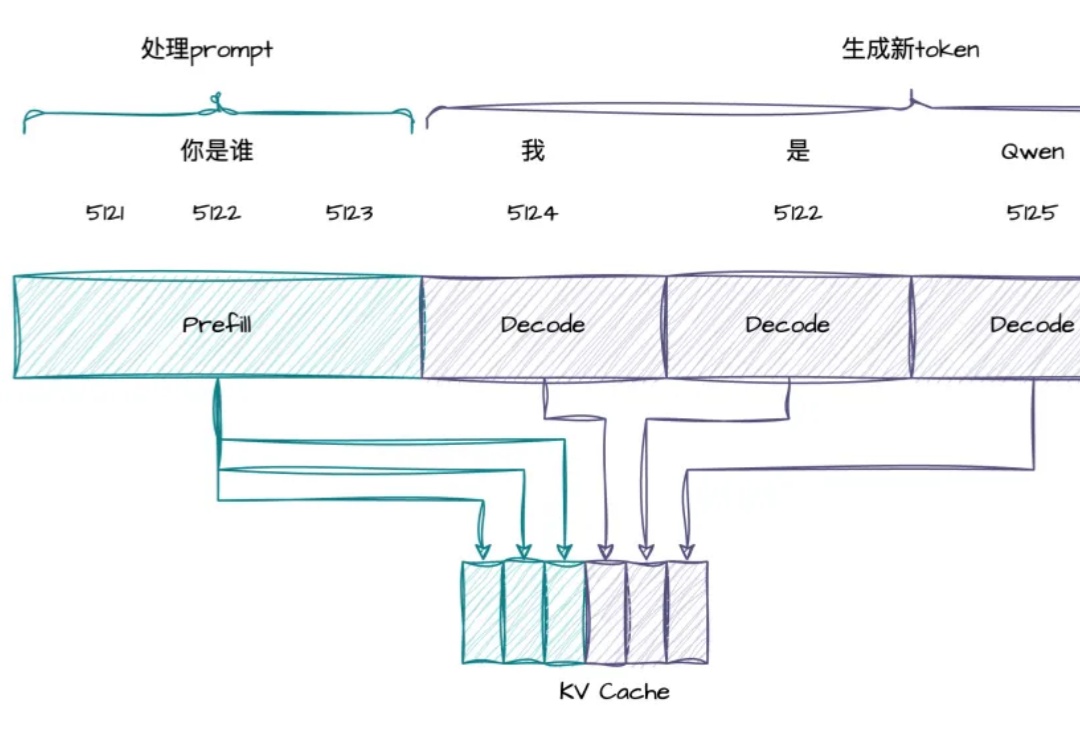
RTP-LLM 是阿里巴巴大模型预测团队开发的高性能 LLM 推理加速引擎。它在阿里巴巴集团内广泛应用,支撑着淘宝、天猫、高德、饿了么等核心业务部门的大模型推理需求。在 RTP-LLM 上,我们实现了一个通用的投机采样框架,支持多种投机采样方法,能够帮助业务有效降低推理延迟以及提升吞吐。
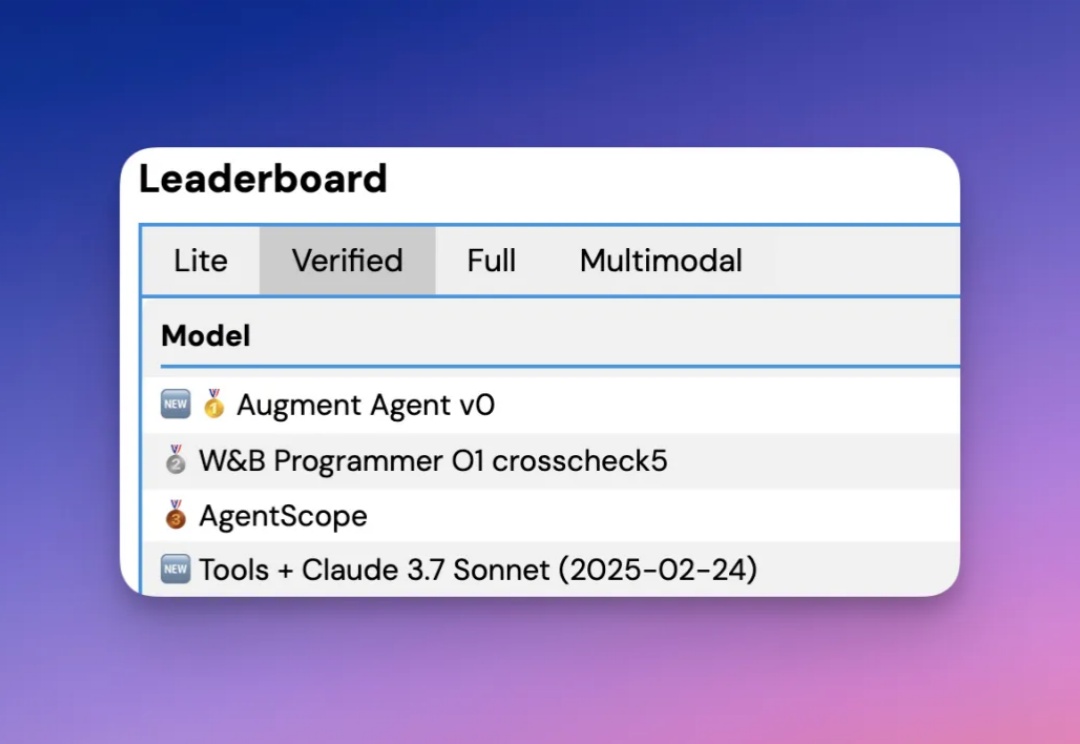
根据官方介绍,Augment Agent 是首个转为大型代码库工作的专业软件工程师设计的 AI 编码助手,上下文支持 200K ,也就是 20 万的 token 啊。

代码截图泄露,满血版o3、o4-mini锁定下周!更劲爆的是,一款据称是OpenAI的神秘模型一夜爆红,每日处理高达260亿token,是Claude用量4倍。奥特曼在TED放话:将推超强开源模型,直面DeepSeek挑战。
在大模型迈向推理时代的当下,数学推理能力已成为衡量语言模型智能上限的关键指标。
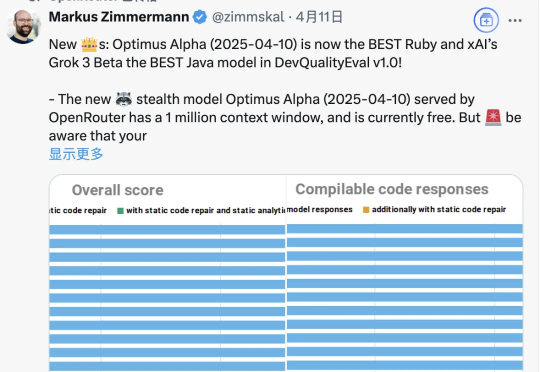
大模型聚合平台OpenRouter新推出的Optimus Alpha,已经处理了772亿Token,平均每天超过200亿。并且这个数字还在上升,日Token处理已超过340亿,排名第二,并在Trending榜单上位列第一。
刚刚,xAI 正式上线 Grok 3 API,一次性推出4种模型,以适配不同应用场景,定价策略灵活,用户可按需选择。同日,谷歌、Anthropic等也推出新的定价策略。