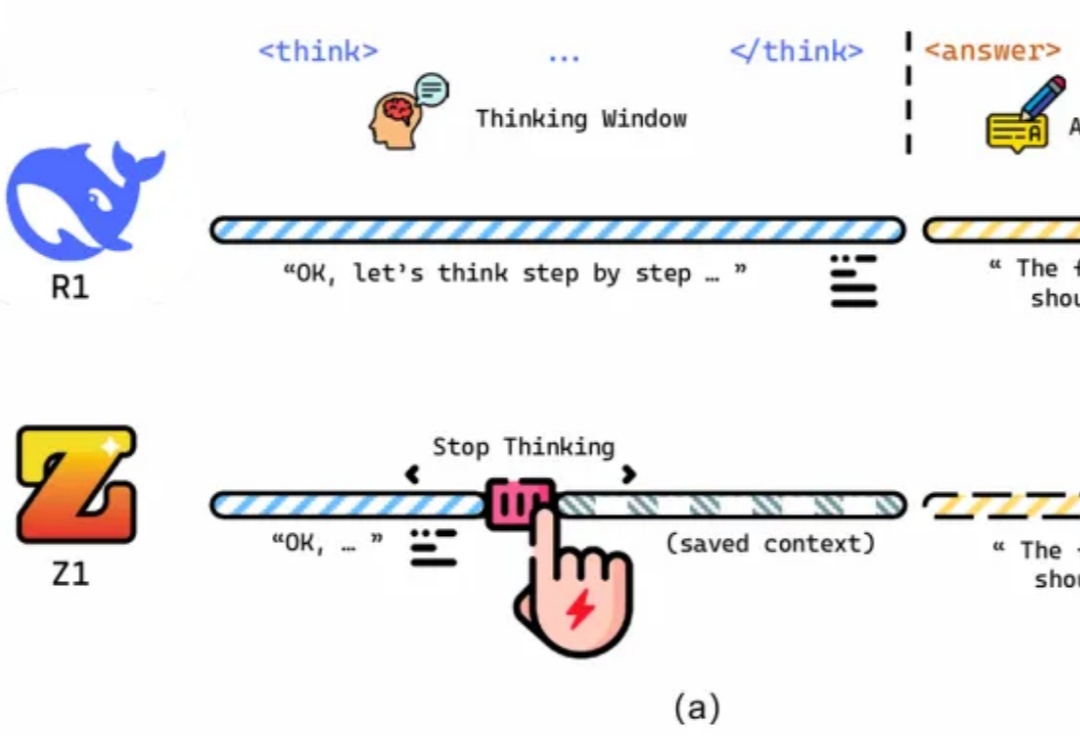
清华耶鲁推理模型新范式:动态推理实现高效测试时扩展,大大节省Token消耗
清华耶鲁推理模型新范式:动态推理实现高效测试时扩展,大大节省Token消耗推理性能提升的同时,还大大减少Token消耗!
来自主题: AI技术研报
8602 点击 2025-04-08 09:25
 搜索
搜索
推理性能提升的同时,还大大减少Token消耗!
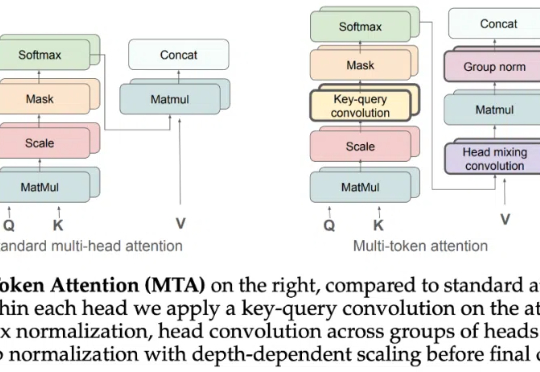
Attention 还在卷自己。

简单的任务,传统的Transformer却错误率极高。Meta FAIR团队重磅推出多token注意力机制(MTA),精准捕捉复杂信息,带来模型性能飞升!
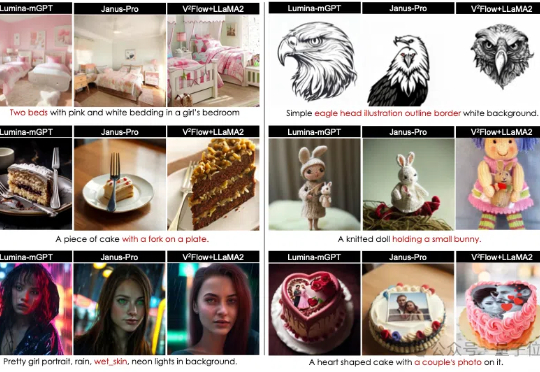
视觉Token可以与LLMs词表无缝对齐了!
刚刚,Local AI 领域的 Libra 团队发布了一段最新技术演示视频,展示了用户通过自然语言交互直接生成 Agent,并利用本地消费级算力支持 Agent 进行长程 (Long-Horizon) 推理,最终完成复杂任务。

它名为 Uni-3DAR,来自深势科技、北京科学智能研究院及北京大学,是一个通过自回归下一 token 预测任务将 3D 结构的生成与理解统一起来的框架。据了解,Uni-3DAR 是世界首个此类科学大模型。并且其作者阵容非常强大,包括了深势科技 AI 算法负责人柯国霖、中国科学院院士鄂维南、深势科技创始人兼首席科学家和北京科学智能研究院院长张林峰等。

DeepSeek-R1掀起新一轮购卡潮的同时,AMD的含金量也上升了。

老黄在GTC 2025大会上,再次亮出了英伟达未来GPU路线图。随着推理token的暴增,AI计算需要全新的范式,下一代BlackWell Ultra、Vera Rubin就是最强的回应。
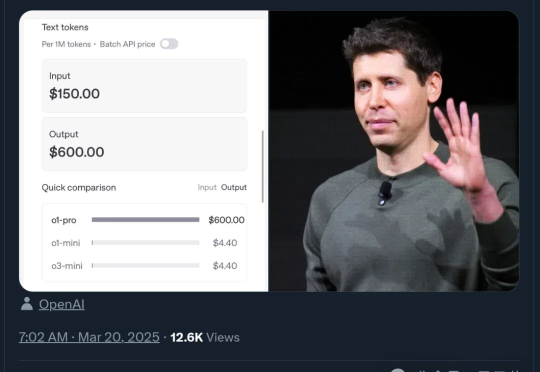
比DeepSeek-R1贵270倍,OpenAI史上最贵模型来了!

当我们看到一张猫咪照片时,大脑自然就能识别「这是一只猫」。但对计算机来说,它看到的是一个巨大的数字矩阵 —— 假设是一张 1000×1000 像素的彩色图片,实际上是一个包含 300 万个数字的数据集(1000×1000×3 个颜色通道)。每个数字代表一个像素点的颜色深浅,从 0 到 255。