
全球AI工厂4万亿激战!这家国产厂商领先一个身位了
全球AI工厂4万亿激战!这家国产厂商领先一个身位了Omdia这份名为《2026全球AI工厂市场格局》的报告,点明了新时代的核心逻辑——决定胜负的,不再是谁拥有更多GPU,而是谁能够更高效地把“电力+算力+数据”转化为真正有价值的Token。
来自主题: AI资讯
8159 点击 2026-05-30 10:06
 搜索
搜索
Omdia这份名为《2026全球AI工厂市场格局》的报告,点明了新时代的核心逻辑——决定胜负的,不再是谁拥有更多GPU,而是谁能够更高效地把“电力+算力+数据”转化为真正有价值的Token。

当Token开始进入套餐表,运营商试图扮演的角色,正在从“连接服务商”进一步变成“AI 算力入口”。就像当年电网把发电厂的电送进千家万户,运营商正在试图把智算中心里的算力,通过套餐和账单体系,变成像水、像电一样可以按月购买、按量消耗的公共资源。

所有人都在比谁的模型参数更大,但真正决定AI能不能落地的,其实是另一件没那么性感的事:一颗Token,能不能被稳定、便宜、规模化地生产出来。死磕这件事的,是一支从中国超级计算体系里走出来的年轻团队,是石科技。
编辑|Panda 数学正在迎来 AI 革命。 最近几个月尤为明显。比如,就在前几天,Google DeepMind 新论文宣布其最新系统 AlphaProof Nexus 在一次自主运行中,解决了 3

GPT-5.5 把进攻性网络安全最难的 7 个基准全部打穿,92.4% 正确率,评估体系直接失灵。AI 黑客能力每 6 个月翻一倍,而衡量它有多危险的尺子,已经先被干碎了。
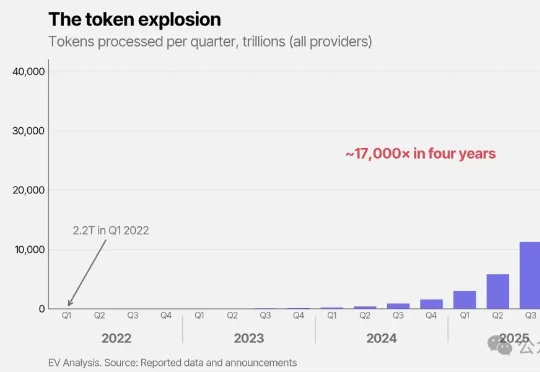
Epoch AI刚刚发布的《梯度更新》报告,做了一件简单粗暴的事:把全球所有Blackwell芯片能处理的Token数量算出来,再和实际需求一比。结论只有一个字——不够。

刚刚,清华团队开源硬核Agent系统PilotDeck,在开发者圈已经传疯了。项目独立建舱,记忆可视可改,Token还能省一大半。从此,一个人,就是一支AI军团!

你有没有想过,我们每天用的 AI 大模型,可能在某些词汇上天生就有缺陷?不是因为训练数据不够,不是因为算力不足,而是因为语言本身的规律——那些用得少的词,模型就是学不好。更让人意外的是,这个问题早在 2025 年就被一家中国创业公司系统性地发现并解决了。

就在几天前(5月22日),DeepSeek官方扔出了一枚重磅炸弹:DeepSeek-V4-Pro将在5月底结束优惠后,永久降价至原价的四分之一。各大媒体瞬间被诸如“白菜价”、“夯爆了”的标题刷屏。看看这组惊人的新定价:每百万Token输出6元,输入(缓存未命中)3元,而输入(缓存命中)仅仅只要0.025元!

每周25万亿tokens的真实流量、估值一年翻倍——OpenRouter拿下1.13亿美元B轮融资。