
在一台1970年代的PDP-11上训练Transformer需要多久?答案是5.5分钟
在一台1970年代的PDP-11上训练Transformer需要多久?答案是5.5分钟试想一下,如果把当下大火的大模型技术带回 1970 年,会发生什么?
来自主题: AI技术研报
8855 点击 2026-04-14 15:45
 搜索
搜索
试想一下,如果把当下大火的大模型技术带回 1970 年,会发生什么?
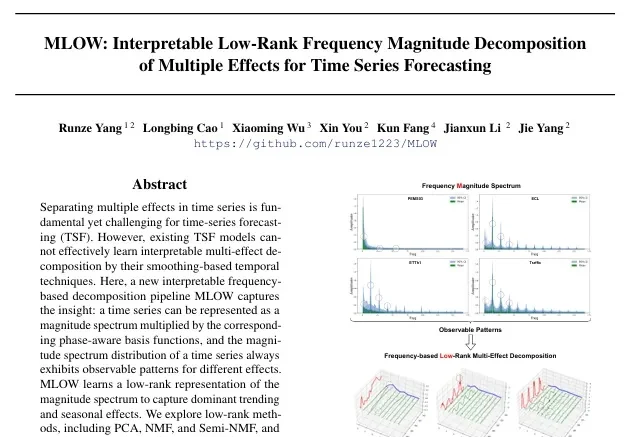
在时间序列预测领域,深度模型如iTransformer、PatchTST虽然性能强劲,却长期困于“黑盒”困境——预测准,但说不出为什么。

第一篇论文来自字节SEED团队, 打了一些基础; 《Over-Tokenized Transformer》。 论文标题看上去在讨论“过度分词”。 而重点必然是在第二篇上—— DeepSeek公司的学术成果Engram。 《Conditional Memory via Scalable Lookup》 也就是Engram模块所出处的论文。

ICLR论文STEM架构率先提出「查表式记忆」架构,早于DeepSeek Engram三个月。它将Transformer的FFN从动态计算改为静态查表,用token索引的embedding表直接读取记忆,彻底解耦记忆容量与计算开销。

Transformer不保?今天,CMU普林斯顿原班人马杀回,新一代开源架构Mamba-3震撼降临。15亿参数战力爆表,性能比Transformer飙升4%。
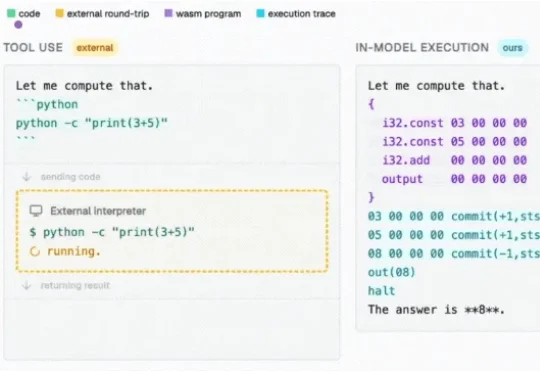
LLM推理已经顶尖,精确计算却跟不上。这局怎么破?卡帕西点赞的解决方法来了,在大模型内部构建一台原生计算机。新方法不搞外包那一套(不依赖任何外部工具),直接在Transformer权重里内嵌可执行程序。

终结Transformer的架构即将诞生!奥特曼最新访谈豪言,下一代AI架构彻底颠覆Transformer,LSTM的命运或将再次上演。
当 Transformer 席卷计算机视觉领域,高分辨率图像、超长序列任务带来的算力与显存瓶颈愈发凸显:标准 Softmax 注意力的二次复杂度,让 70K+token 的超分辨率任务直接显存爆炸,高分辨率图像分割、检测的推理延迟居高不下。

就在刚刚,Moonshot AI(月之暗面)发布了一项足以撼动 Transformer 底层的研究:《Attention Residuals》。海外科技大 V,谷歌高级AI产品经理 Shubham Saboo 直接开启了“高赞”模式:“他们触碰了那个十年没人敢碰的部分。”
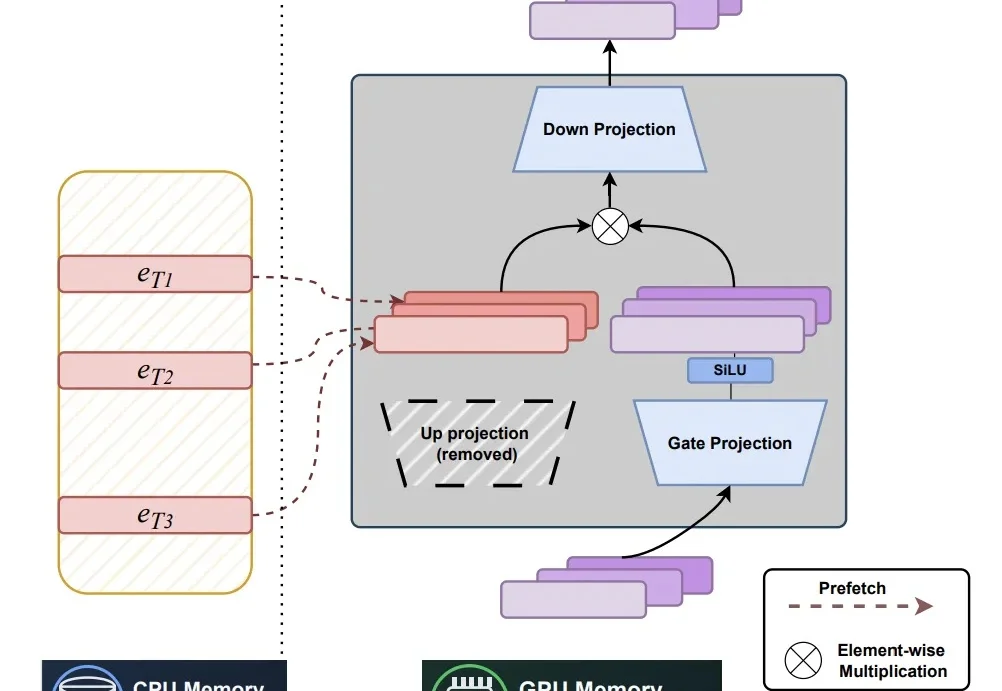
近年来,随着大语言模型规模与知识密度不断提升,研究者开始重新思考一个更本质的问题:模型中的参数应如何被组织,才能更高效地充当「记忆」。