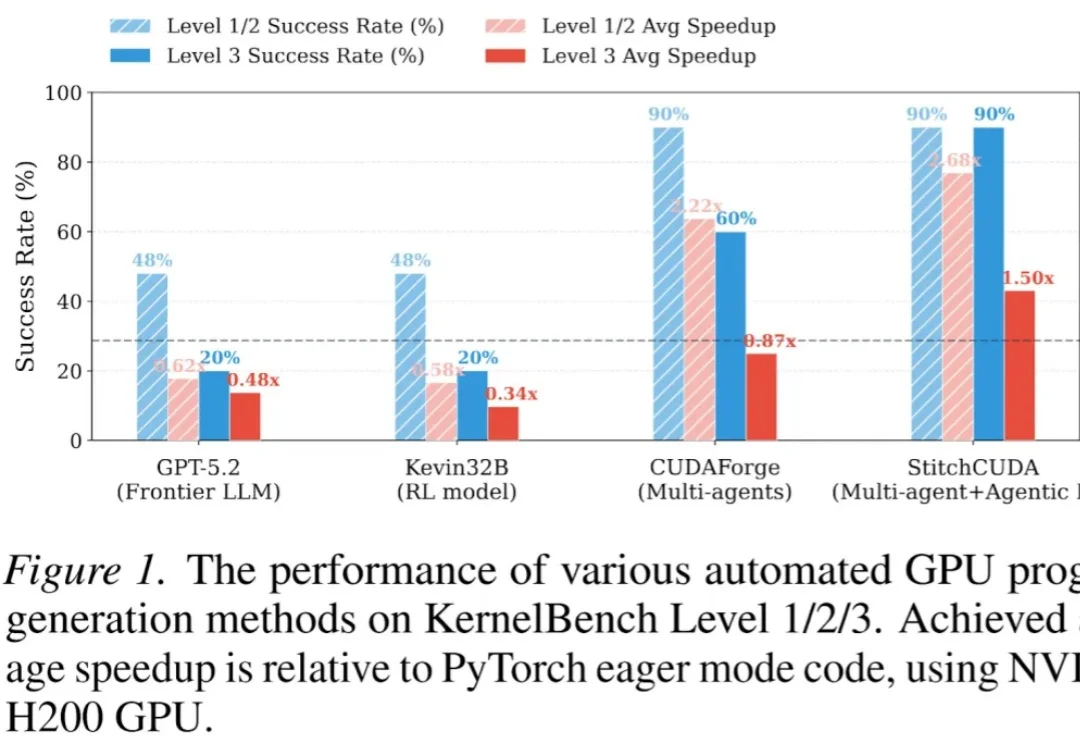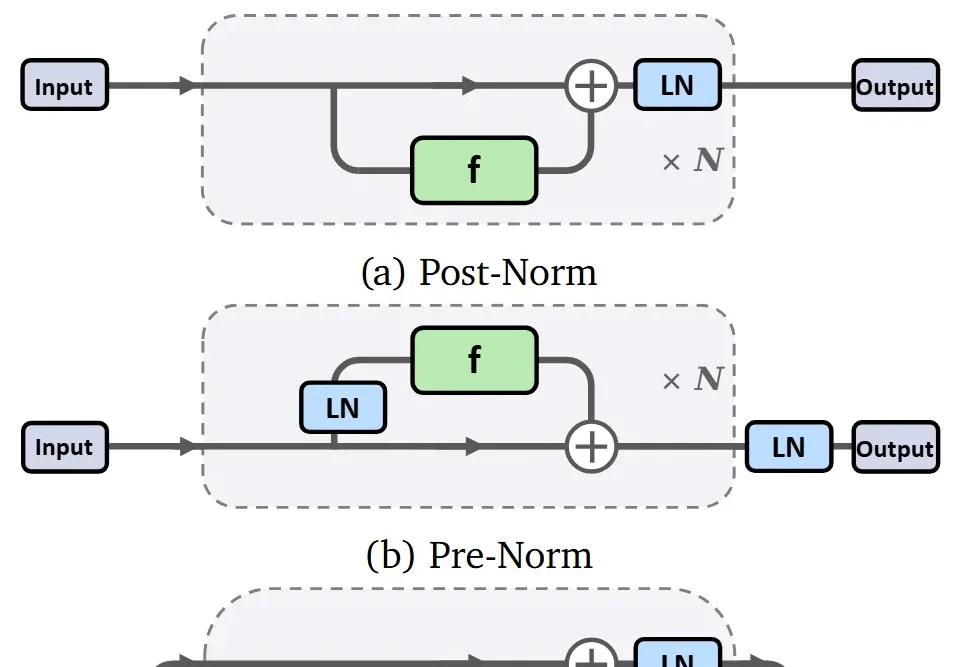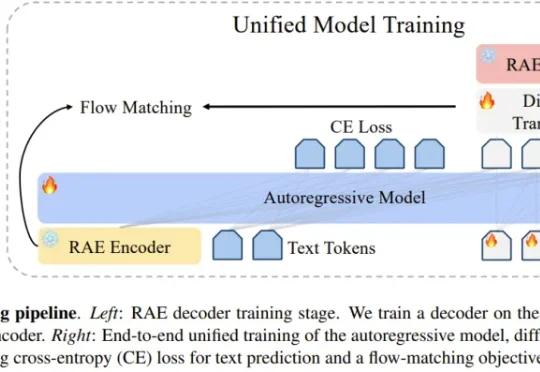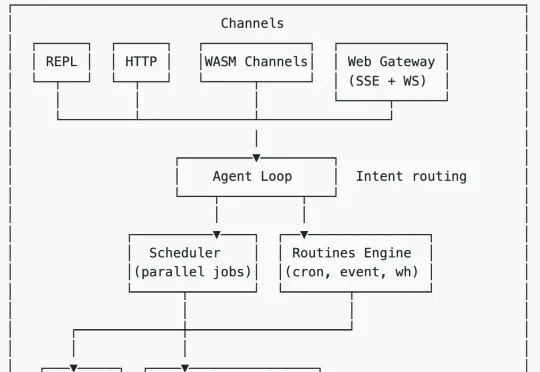
用Rust重写OpenClaw,Transformer作者下场造了安全版「龙虾」
用Rust重写OpenClaw,Transformer作者下场造了安全版「龙虾」面对 OpenClaw(龙虾)可能存在的「恶意利用用户数据和资金」的重大风险,Transformer 八子之一 Illia Polosukhin 出手了。今天,Illia Polosukhin 在 Reddit 上发了一则帖子,深谈了其使用 Rust 来构建安全版 OpenClaw 的心路历程,引起了热议。
来自主题: AI资讯
8652 点击 2026-03-07 11:10