UltraRAG 3.0 发布:拒绝“盲盒”开发,让每一行推理逻辑都清晰可见
UltraRAG 3.0 发布:拒绝“盲盒”开发,让每一行推理逻辑都清晰可见今天,清华大学 THUNLP 实验室、东北大学 NEUIR 实验室、OpenBMB 、面壁智能与 AI9Stars 联合发布 UltraRAG 3.0 ,针对上述痛点,为科研工作者与开发者打造更懂开发者的技术框架,具备 3 大核心优势:
来自主题: AI资讯
11435 点击 2026-01-24 15:14
 搜索
搜索
今天,清华大学 THUNLP 实验室、东北大学 NEUIR 实验室、OpenBMB 、面壁智能与 AI9Stars 联合发布 UltraRAG 3.0 ,针对上述痛点,为科研工作者与开发者打造更懂开发者的技术框架,具备 3 大核心优势:

英特尔发布年度旗舰AI PC芯片——第三代酷睿Ultra系列处理器(代号Panther Lake)。这是首款基于Intel 18A制程(1.8nm级)的计算平台,将AI PC引入埃米时代,端侧AI算力多达180TOPS。
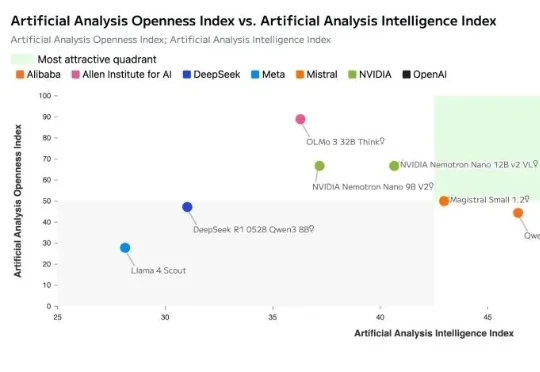
就在刚刚,英伟达正式开源发布了其新一代AI模型:NVIDIA Nemotron 3。Nemotron 3 系列由三种型号组成:Nano、Super 和 Ultra。官方介绍其具备强大的智能体、推理和对话能力。

太劲爆了!不过半月,谷歌DeepMind终于放出了IMO最强金牌模型——Gemini 3 Deep Think。今天,Gemini 3 Deep Think已在Gemini App上线,所有Ultra用户即可体验。
就在刚刚,DeepSeek 又悄咪咪在 Hugging Face 上传了一个新模型:DeepSeek-Math-V2。顾名思义,这是一个数学方面的模型。它的上一个版本 ——DeepSeek-Math-7b 还是一年多以前发的。当时,这个模型只用 7B 参数量,就达到了 GPT-4 和 Gemini-Ultra 性能相当的水平。相关论文还首次引入了 GRPO,显著提升了数学推理能力。

一位在互联网上近乎「隐形」的27岁创始人,却同时赢得奥特曼与孙正义的重注,豪言要打造一个「现代贝尔实验室」。

就在今天,OpenAI 与 AWS 官宣建立多年的战略合作伙伴关系。OpenAI 将立即并持续获得 AWS 世界级的基础设施支持,以运行其先进的 AI 工作负载。 AWS 将向 OpenAI 提供配备数十万颗芯片的 Amazon EC2 UltraServers(计算服务器),并具备将计算规模扩展至数千万个 CPU 的能力,以支持其先进的生成式 AI 任务

双11别只盯着打折——真正值得买的,是能让你工作不卡顿、生活不焦虑的效率神器。说到效率神器,AI PC绝对是其中之一。因为现在它们已经搭载了英特尔® 酷睿™ Ultra 200H系列处理器,“打开方式”完全变了样——
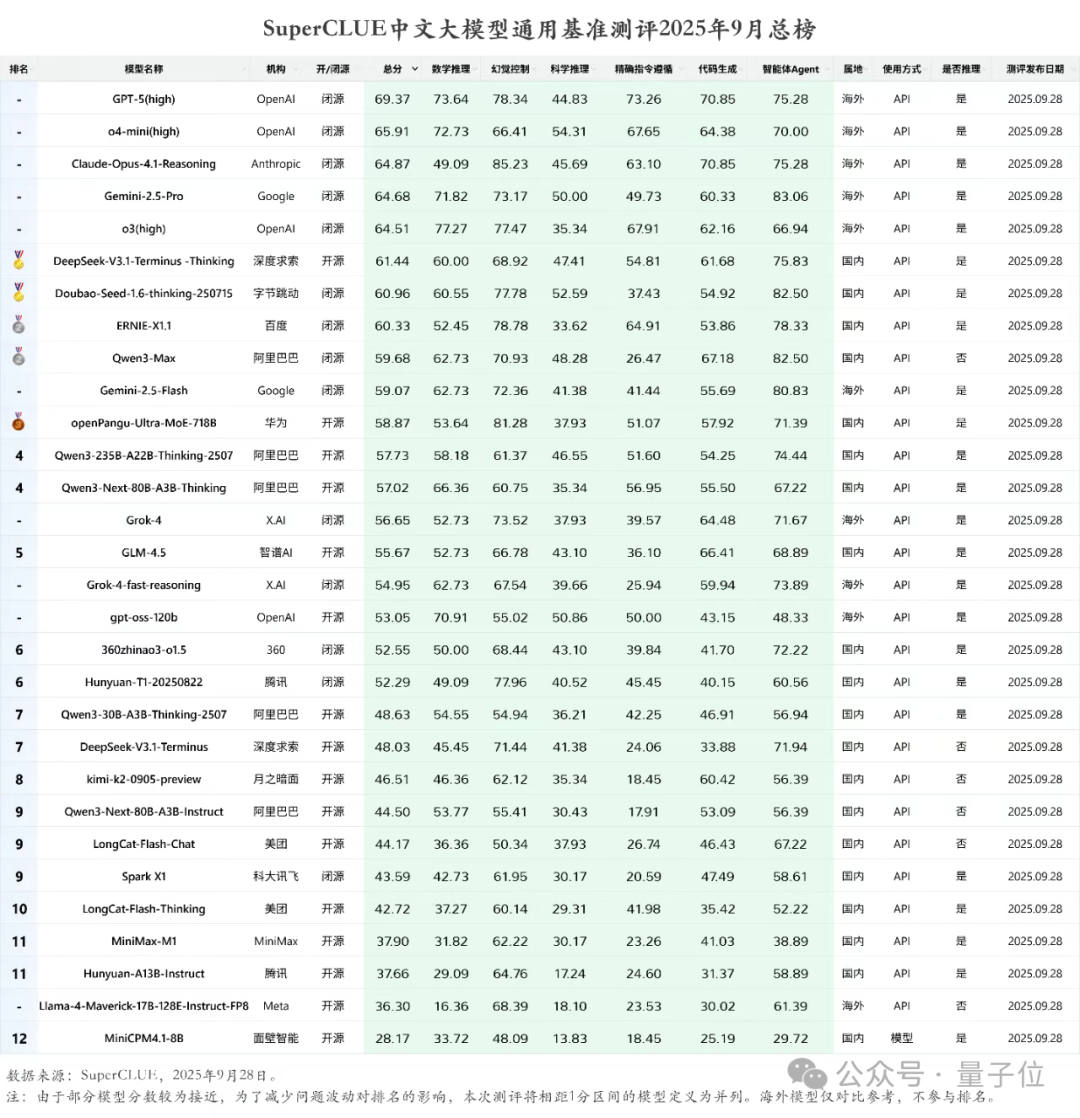
就在最新一期的SuperCLUE中文大模型通用基准测评中,各个AI大模型玩家的成绩新鲜出炉。DeepSeek-V3.1-Terminus-Thinking openPangu-Ultra-MoE-718B Qwen3-235B-A22B-Thinking-2507

在高质量3D生成需求日益增长的背景下,如何高效生成结构精良、几何精细的三维资产,已成为AIGC和数字内容创作领域的关键挑战。