
实测小米最快1T大模型:吞吐量每秒1000+ Tokens,Vibe Coding七秒交付
实测小米最快1T大模型:吞吐量每秒1000+ Tokens,Vibe Coding七秒交付全球大模型的军备竞赛,正在“智商”之外开辟新的战场—— 推理速度。
来自主题: AI产品测评
5527 点击 2026-06-11 09:58
 搜索
搜索
全球大模型的军备竞赛,正在“智商”之外开辟新的战场—— 推理速度。
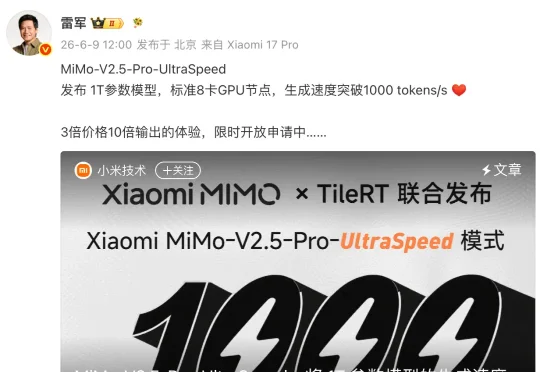
今日,小米MiMo团队与推理系统团队TileRT联合宣布,Xiaomi MiMo-V2.5-Pro的UltraSpeed模式已实现万亿参数(1T)旗舰模型输出速度首次突破1000 tokens/s。
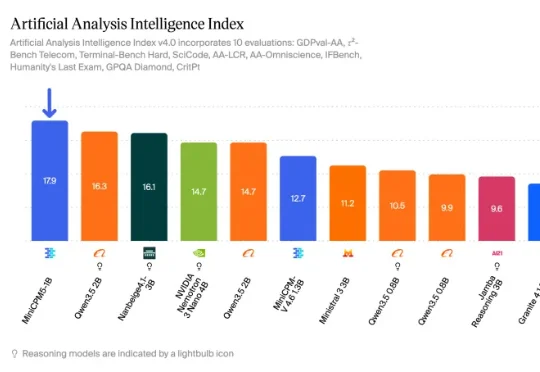
我去搜了下 MiniCPM5-1B 的数据,发现面壁智能刚刚把背后的核心数据集给开源了。一共是两份 L3 级数据集:Ultra-FineWeb-L3 :600B tokens,中英文都有,是目前最大的中文开源合成预训练数据集。
做过 AI 视频的都懂,除了 Seedance 2.0 本身的高定价,废片所烧掉的 token 算力也是一笔不小的开支。但在 Topview 平台,直接把这笔最大试错成本给重新定义了!热门视频生成模型 Seedance 2.0,加上最新的图片生成模型 Image 2,订阅 Ultra Plan,可不限量使用。

今天介绍 Claude Code 上线的一个新功能:/ultrareview。一句话概括:它会在云端同时派出多个 AI 审查员,帮你在合并代码之前把 Bug 揪出来。这个功能其实在上周 Claude Opus 4.7 发布时就提到了,当时 Anthropic 在发布公告里写的是:

如果你看过最近的人形机器人演示,大概率会被它们的运动能力震撼到。

英特尔,真是越来越会玩了—— 因为它把优化CPU这件事的痛点,直接搞得像送外卖似的:

Claude Code 今天上了个新功能叫 /ultraplan,做的事情很好理解:在动手写代码之前,先在网页上给你看一份完整的实施方案。你可以读,可以改,甚至可以在方案里给 Claude 留评论。觉得没问题了,点一下「批准」,Claude 才开始动手。
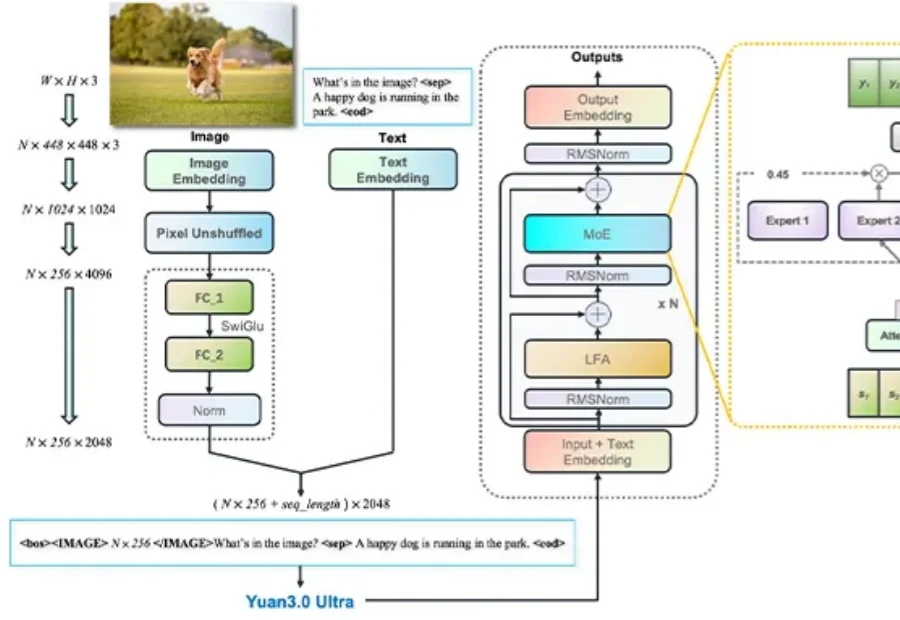
告别Token老虎,给大模型来了个“减脂增肌”。
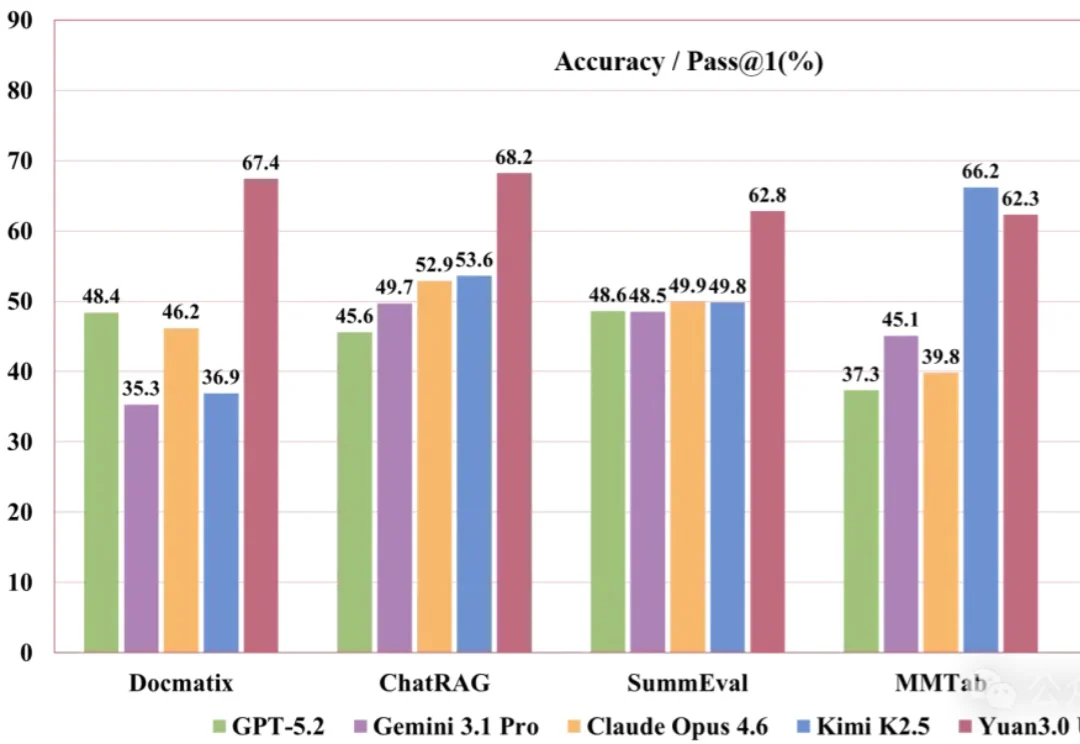
刚刚,YuanLab.ai团队正式开源发布源Yuan3.0 Ultra多模态基础大模型。