
LaPha:你的Agent轨迹其实嵌入在一个Poincaré球?
LaPha:你的Agent轨迹其实嵌入在一个Poincaré球?在经典强化学习问题中,动作空间通常是离散且有限的。例如在围棋中,一步棋就是一次行动;在机器人控制或视觉 - 语言 - 行动(VLA)模型中,动作往往来自一个有限的控制指令集合。
来自主题: AI技术研报
6351 点击 2026-03-18 14:54
 搜索
搜索
在经典强化学习问题中,动作空间通常是离散且有限的。例如在围棋中,一步棋就是一次行动;在机器人控制或视觉 - 语言 - 行动(VLA)模型中,动作往往来自一个有限的控制指令集合。
在具身智能的发展路径中,视觉 - 语言 - 动作(VLA)模型正逐步成为通用操作任务的核心框架。但当任务进入长程规划、柔性物体操作、精细双臂协同、动态交互等复杂场景时,VLA 仍然面临两个根本性挑战:

不卷VLA,这家公司给机器人造生成式大脑。

用「无本体数采」的方式训练具身模型,灵初智能的这条路径是 VLA 之后行业最热的方向之一。

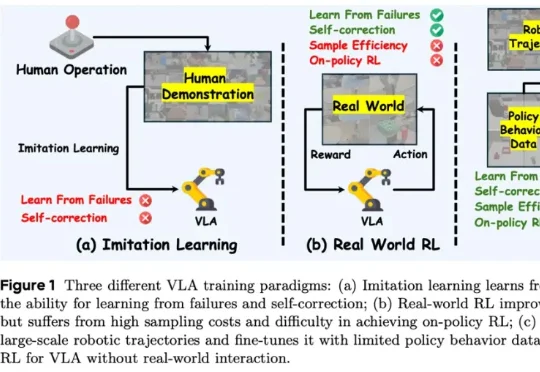
是不是经常纠结于 VLA(视觉 - 语言 - 动作)模型的训练技巧?面对层出不穷的 VLA 算法,是不是常常感到眼花缭乱,不知道哪种数据模态、训练策略最有效? 别急,丰田研究院(TRI)和清华大学刚刚

MMLab@NTU联合中山大学的最新研究,给出了一份从入门到精通的终极“菜谱”——VLANeXt。这项研究没有简单提出一个新模型了事,而是系统性地从12个关键维度,深度剖析了VLA的设计空间。从基础组件到感知要素,再到动作建模的额外视角,每一步都有扎实的实验支撑。
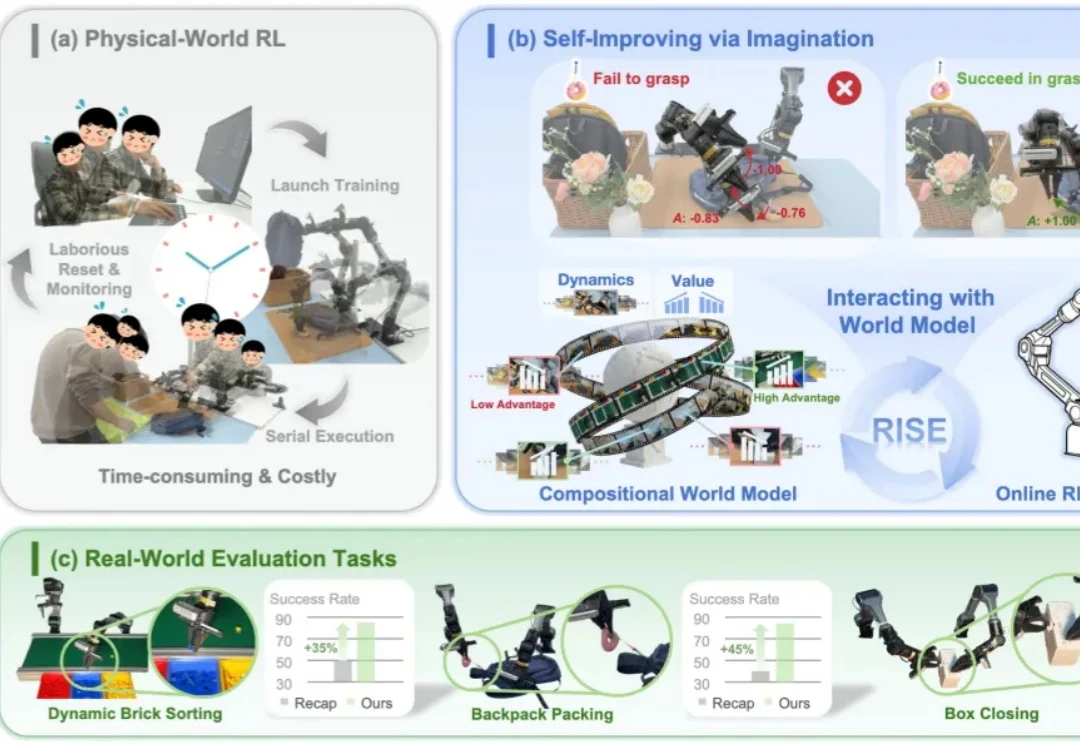
香港科技大学 PEI-Lab 与字节跳动 Seed 团队近期提出的 WMPO(World Model-based Policy Optimization),正是这样一种让具身智能在 “想象中训练” 的新范式。该方法无需在真实机器人上进行大规模强化学习交互,却能显著提升策略性能,甚至涌现出 自我纠错(Self-correction) 行为。

机器之心编辑部 整个具身智能领域都在探索世界模型的实用化路径。这个被寄予厚望的「数字模拟器」,本应成为机器人训练的核心工具,却因物理保真度低等问题成为「空中楼阁」。 去年年中,谷歌发布了 Genie-
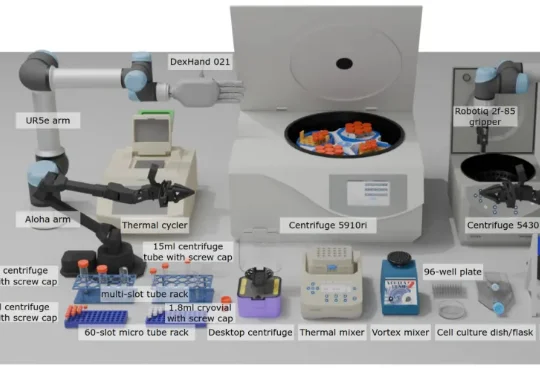
现有 VLA 模型的研究和基准测试多局限于家庭场景(如整理餐桌、折叠衣物),缺乏对专业科学场景(尤其是生物实验室)的适配。生物实验室具有实验流程结构化、操作精度要求高、多模态交互复杂(透明容器、数字界面)等特点,是评估 VLA 模型精准操作、视觉推理和指令遵循能力的理想场景之一。

极佳视界具身大模型 GigaBrain-0.5M*,以世界模型预测未来状态驱动机器人决策,并实现了持续自我进化,超越π*0.6 实现 SOTA!该模型在叠衣、冲咖啡、折纸盒等真实任务中实现接近 100% 成功率;相比主流基线方法任务成功率提升近 30%;基于超万小时数据训练,其中六成由自研世界模型高保真合成。