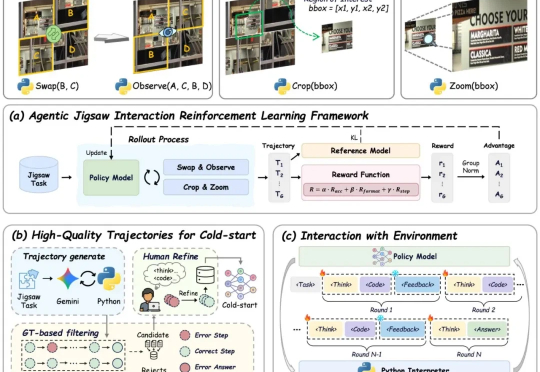
AGILE:视觉学习新范式!自监督+交互式强化学习助力VLMs感知与推理全面提升
AGILE:视觉学习新范式!自监督+交互式强化学习助力VLMs感知与推理全面提升现有视觉语言大模型(VLMs)在多模态感知和推理任务上仍存在明显短板:1. 对图像中的细粒度视觉信息理解有限,视觉感知和推理能力未被充分激发;2. 强化学习虽能带来改进,但缺乏高质量、易扩展的 RL 数据。
来自主题: AI技术研报
7816 点击 2025-10-21 15:30
 搜索
搜索
现有视觉语言大模型(VLMs)在多模态感知和推理任务上仍存在明显短板:1. 对图像中的细粒度视觉信息理解有限,视觉感知和推理能力未被充分激发;2. 强化学习虽能带来改进,但缺乏高质量、易扩展的 RL 数据。

复旦大学NLP实验室研发Game-RL,利用游戏丰富视觉元素和明确规则生成多模态可验证推理数据,通过强化训练提升视觉语言模型的推理能力。创新性地提出Code2Logic方法,系统化合成游戏任务数据,构建GameQA数据集,验证了游戏数据在复杂推理训练中的优势。
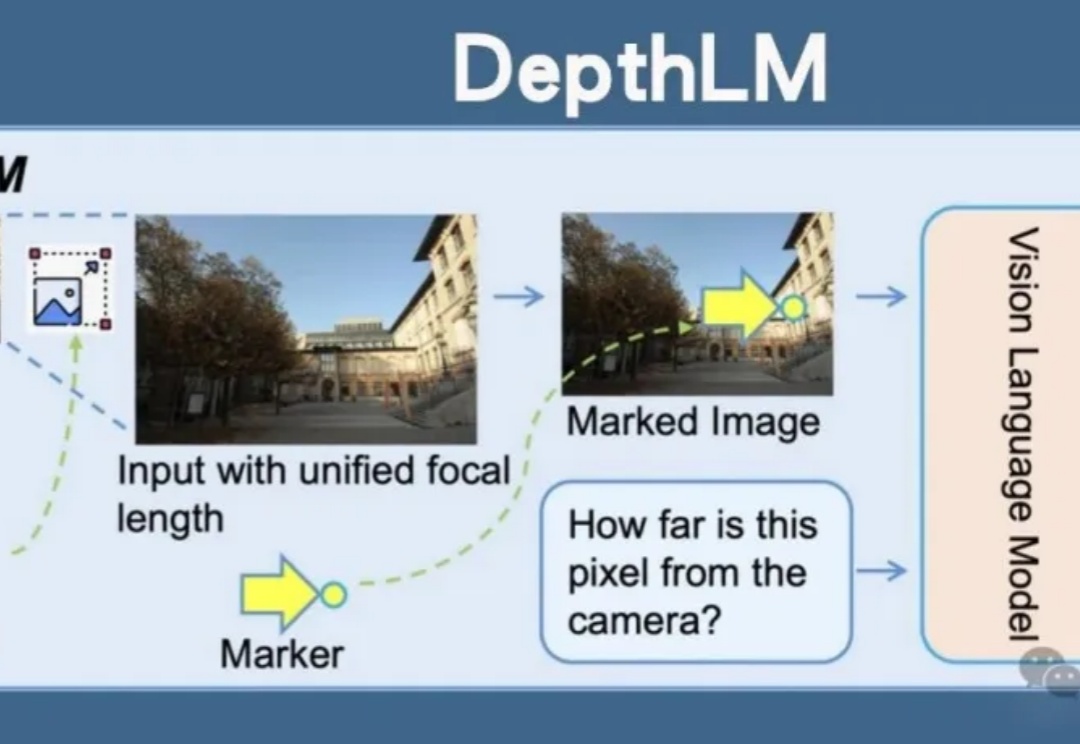
Meta开源DepthLM,首证视觉语言模型无需改架构即可媲美纯视觉模型的3D理解能力。通过视觉提示、稀疏标注等创新策略,DepthLM精准完成像素级深度估计等任务,解锁VLM多任务处理潜力,为自动驾驶、机器人等领域带来巨大前景。
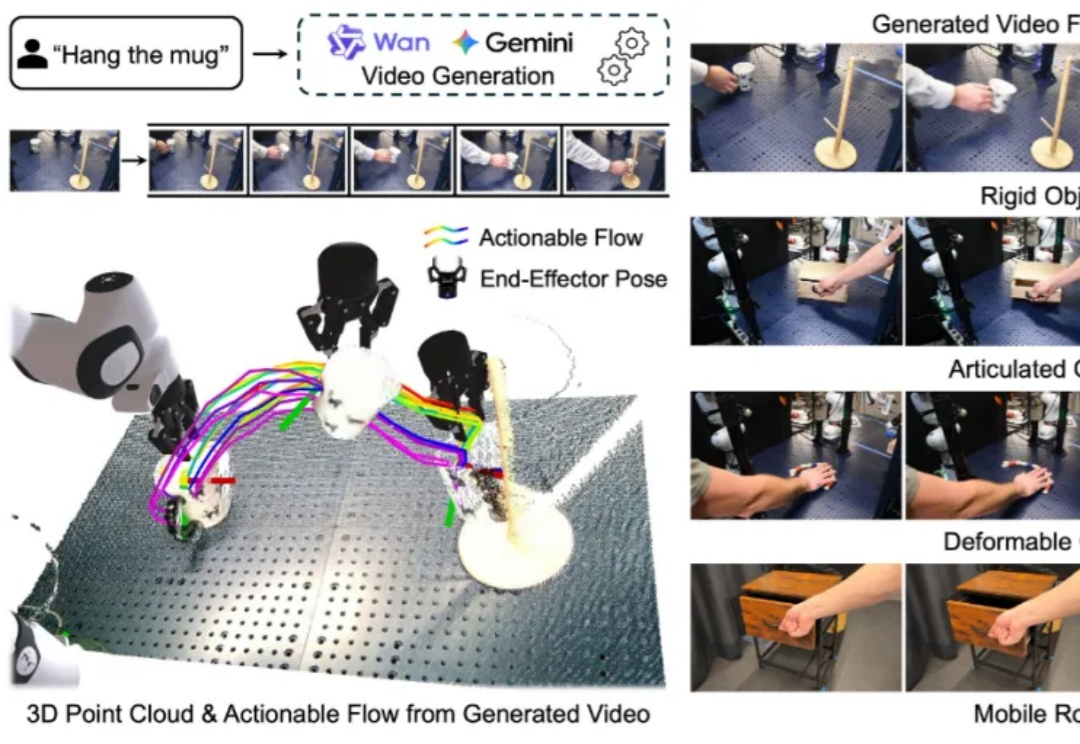
构建能够在新环境中、无需任何针对性训练就能执行多样化任务的通用机器人,是机器人学领域一个长期追逐的圣杯。近年来,随着大型语言模型(LLMs)和视觉语言模型(VLMs)的飞速发展,许多研究者将希望寄托于视觉 - 语言 - 动作(VLA)模型,期望它们能复刻 LLM 和 VLM 在泛化性上取得的辉煌。

游戏理解领域模型LynkSoul VLM v1,在游戏场景中表现显著超过了包括GPT-4o、Claude 4 Sonnet、Gemini 2.5 Flash等一众顶尖闭源模型。背后厂商逗逗AI,亦在现场吸引了不少关注的目光。
VLA模型通常建立在预训练视觉语言模型(VLM)之上,仅基于2D图像-文本数据训练,缺乏真实世界操作所需的3D空间理解能力。
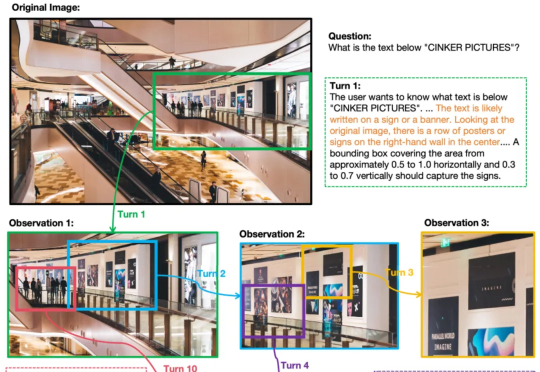
OpenAI o3的多轮视觉推理,有开源平替版了。并且,与先前局限于1-2轮对话的视觉语言模型(VLM)不同,它在训练限制轮数只有6轮的情况下,测试阶段能将思考轮数扩展到数十轮。

苹果在 Hugging Face上放大招了!这次直接甩出两条多模态主线:FastVLM主打「快」,字幕能做到秒回;MobileCLIP2主打「轻」,在 iPhone 上也能起飞。更妙的是,模型和Demo已经全开放,Safari网页就能体验。大模型,真·跑上手机了。

在这场以大型语言模型(LLM)为核心的 AI 浪潮中,苹果似乎一直保持着低调,很少出现在技术报道的前沿。尽管如此,时不时地,该公司也能拿出一些非常亮眼的研究成果,比如能在 iPhone 上直接运行的高效视觉语言模型 FastVLM。
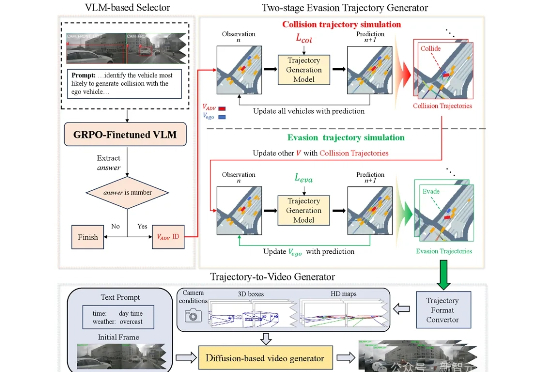
浙江大学与哈工大(深圳)联合推出SafeMVDrive,利用扩散模型结合VLM实现批量化多视角真实域的安全关键视频生成。该方法在保持画质与真实感的同时,显著增强了驾驶场景的危险性。生成的场景用于端到端自动驾驶系统的极限压测,可使得模型的碰撞率提升50倍。