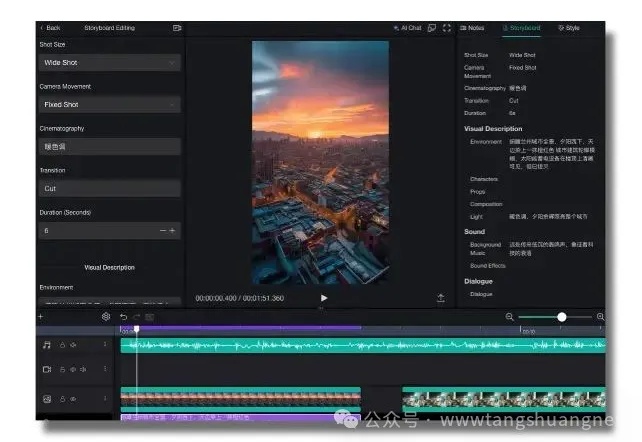
历经2个月,我的第一款真正意义上的AI产品上线
历经2个月,我的第一款真正意义上的AI产品上线大家好,这两个月我完成了一款产品——Videa。虽然过去一年,我做了很多东西,但是部分是套壳,部分是把别人的想法做出来,真正我一直想做的,其实是一款借助AI创作短视频的产品。现在,我把它做出来了。
来自主题: AI资讯
7634 点击 2025-06-05 16:20
 搜索
搜索
大家好,这两个月我完成了一款产品——Videa。虽然过去一年,我做了很多东西,但是部分是套壳,部分是把别人的想法做出来,真正我一直想做的,其实是一款借助AI创作短视频的产品。现在,我把它做出来了。

智源研究院发布开源模型Video-XL-2,显著提升长视频理解能力。该模型在效果、处理长度与速度上全面优化,支持单卡处理万帧视频,编码2048帧仅需12秒。
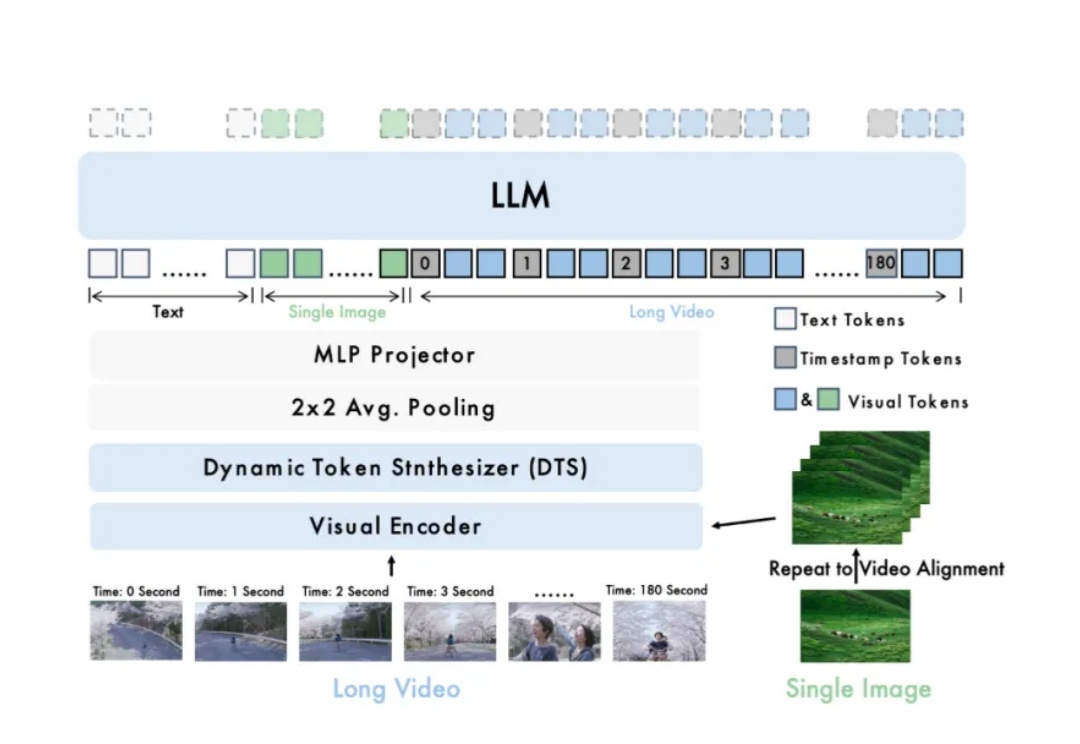
长视频理解是多模态大模型关键能力之一。尽管 OpenAI GPT-4o、Google Gemini 等私有模型已在该领域取得显著进展,当前的开源模型在效果、计算开销和运行效率等方面仍存在明显短板。

多模态大模型(MLLM)在静态图像上已经展现出卓越的 OCR 能力,能准确识别和理解图像中的文字内容。MME-VideoOCR 致力于系统评估并推动MLLM在视频OCR中的感知、理解和推理能力。

就是这两个黄毛小伙子,他们试图建立新的教育体系。 他们为学生创建了一种制作自定义视频教程的方法,一键生成所有科目的讲解视频,比真人老师讲的更好更仔细,就像可汗学院一样,并允许他们像与真正的导师/老师交谈一样进行互动,让每位学生都有私教老师。

近年来,生成式人工智能的快速发展,在文本和图像生成领域都取得了很大的成功。
在上一篇研究图谱中,我们指出医疗领域很可能是 Vertical Agent 最先落地的领域,其中最有代表性的公司之一是 OpenEvidence,一款专为医生设计的 AI 专业诊断 Copilot。
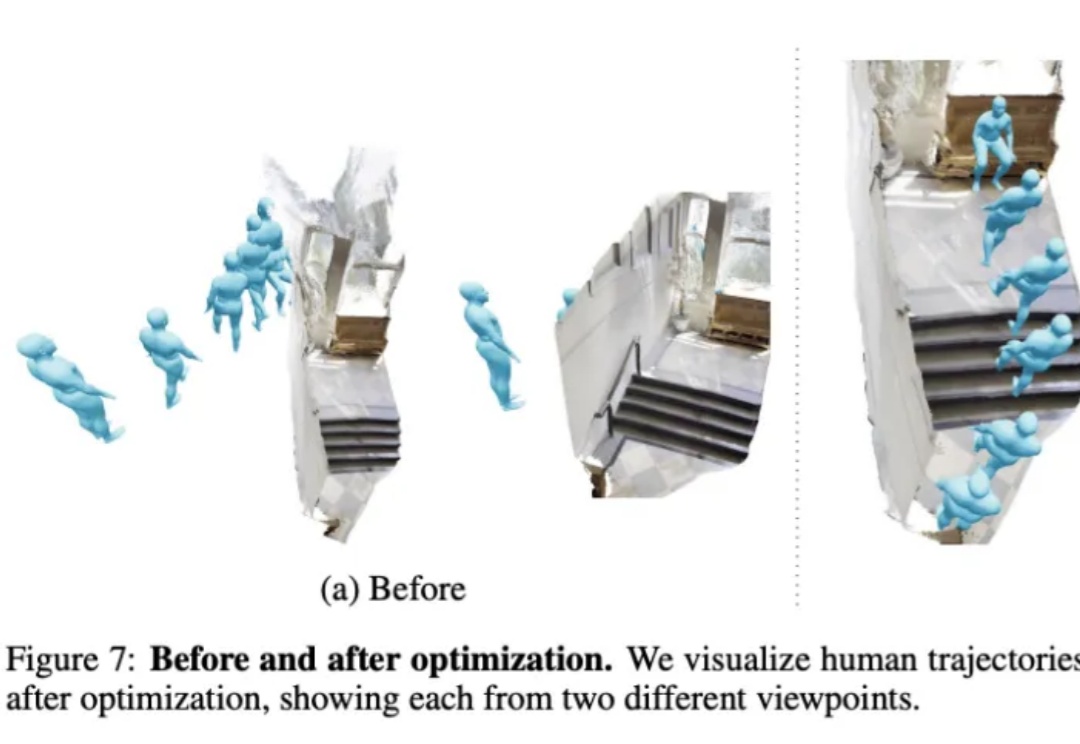
不用动作捕捉,只用一段视频就能教会机器人学会人类动作,效果be like:

随着 Deepseek 等强推理模型的成功,强化学习在大语言模型训练中越来越重要,但在视频生成领域缺少探索。复旦大学等机构将强化学习引入到视频生成领域,经过强化学习优化的视频生成模型,生成效果更加自然流畅,更加合理。并且分别在 VDC(Video Detailed Captioning)[1] 和 VBench [2] 两大国际权威榜单中斩获第一。

a16z (Andreessen Horowitz)是一家风险投资公司,以其多元化的投资领域著称。其热衷于为其投资公司提供策略和资源协助进而帮助它们取得成功。被投资公司包括Airbnb、Meta和Twitter等。Yoko和Justine为其投资合伙人。本次访谈两位合伙人分享了颠覆传统编程方式的AI编程——Vide Coding编程方式。