
ICLR 2026|在「想象」中进化的机器人:港科大×字节跳动Seed提出WMPO,在世界模型中进行VLA强化学习
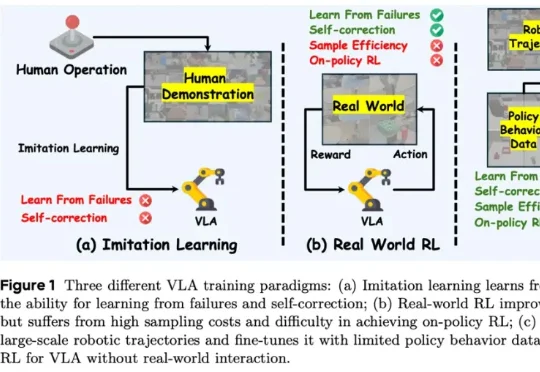
ICLR 2026|在「想象」中进化的机器人:港科大×字节跳动Seed提出WMPO,在世界模型中进行VLA强化学习香港科技大学 PEI-Lab 与字节跳动 Seed 团队近期提出的 WMPO(World Model-based Policy Optimization),正是这样一种让具身智能在 “想象中训练” 的新范式。该方法无需在真实机器人上进行大规模强化学习交互,却能显著提升策略性能,甚至涌现出 自我纠错(Self-correction) 行为。
来自主题: AI技术研报
9488 点击 2026-03-02 14:31