
DeepSeek网页版大升级!随后宕机11小时崩上热搜,新模型真的来了
DeepSeek网页版大升级!随后宕机11小时崩上热搜,新模型真的来了DeepSeek崩上热搜!宕机持续超过8小时,写论文的、角色扮演的和心情不好找AI吐槽的人也都崩溃了。But!这不是一次普通的服务中断,反而被解读为模型升级的前兆。
来自主题: AI资讯
8261 点击 2026-03-30 10:58
 搜索
搜索
DeepSeek崩上热搜!宕机持续超过8小时,写论文的、角色扮演的和心情不好找AI吐槽的人也都崩溃了。But!这不是一次普通的服务中断,反而被解读为模型升级的前兆。
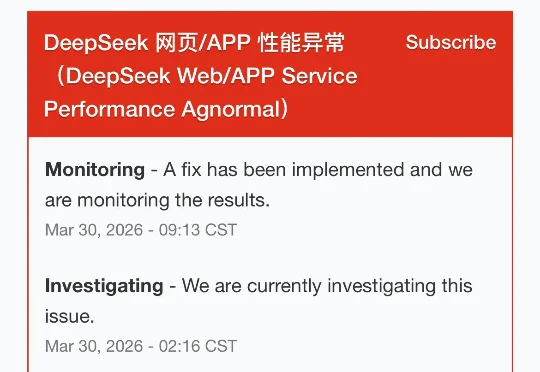
从3月29日晚21时左右起,国内大模型产品DeepSeek的网页端与APP端服务器持续处于崩溃状态,大量用户反馈无法正常访问对话服务。
硅心科技(aiXcoder)发布了一款专为「代码变更应用」场景设计的高性能、轻量级模型 aiX-apply-4B。基准测试结果显示,在 20 多种主流编程语言及 Markdown 等多类型文件格式的测试中,aiX-apply-4B 的平均准确率达到 93.8%,超越 Qwen3-4B 基座模型 62.6% 的准确度
看过 HBO 神剧《硅谷》(Silicon Valley)的朋友,想必都对那个名为 Pied Piper(魔笛手)的虚构公司念念不忘。

Token正在重塑AI时代的价值坐标,它是效率革命的引擎,还是成本失控的暗礁?本期将从Token降本的视角,透视AI时代"新石油"的经济逻辑。
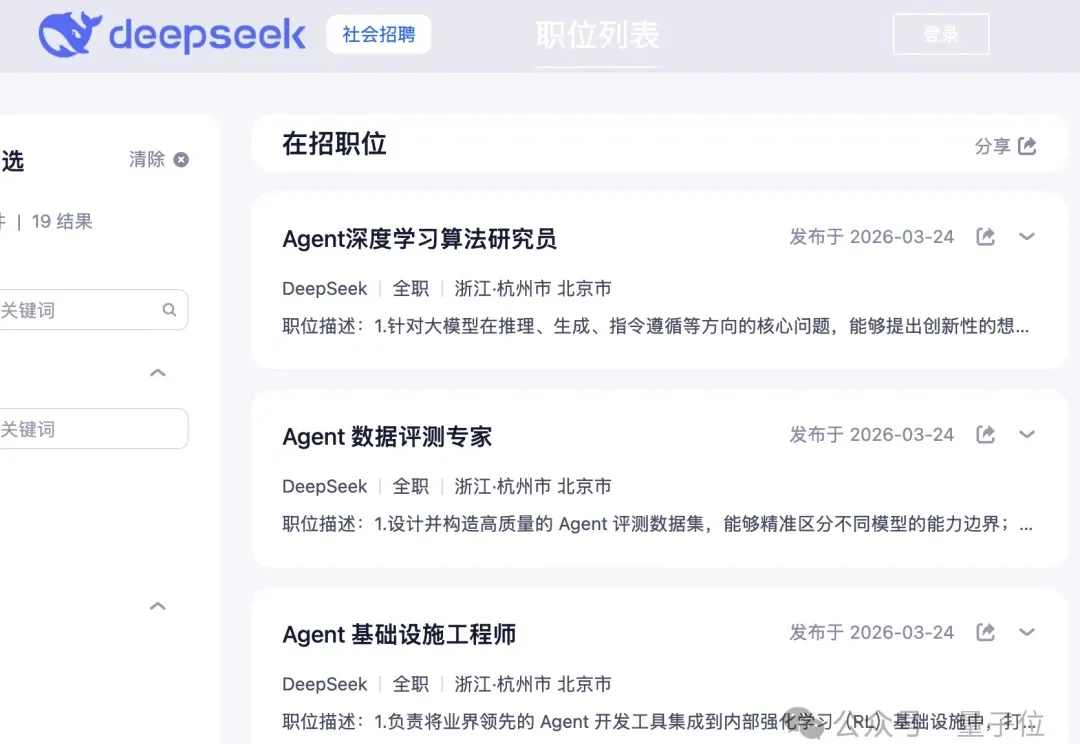
DeepSeek,一口气开放17个招聘岗位。

DeepSeek,又有核心工程师流入江湖—— 郭达雅,V2、V3、R1等一系列模型的核心作者,被曝离职。

占领OpenRouter调用量榜单第一的神秘模型Hunter Alpha,终于揭开神秘面纱—— 既不是GPT,也不是DeepSeek,而是来自小米的万亿旗舰模型MiMo-V2-Pro。

今日凌晨,小米MiMo大模型系列重磅三连更:旗舰基座大模型MiMo-V2-Pro、全模态Agent模型MiMo-V2-Omni、MiMo-V2-TTS,其最新发布的这三大模型都是为优化智能体能力打造。

3月17日,楽天(乐天)集团正式发布了Rakuten AI 3.0模型,号称是“日本国内最大规模的高性能AI模型”。官方宣传的参数量为约7000亿,并且日语特化,Apache 2.0开源许可,还拿了日本经产省和NEDO的GENIAC项目补助。