
梁文锋,被曝融资20亿!
梁文锋,被曝融资20亿!今日,据外媒The Information报道,DeepSeek正首次寻求外部融资,目标估值超过100亿美元(约合人民币681.8亿元)。据多位知情人士透露,DeepSeek已开始与投资人接触,计划融资至少3亿美元(约合人民币20.5亿元),以补充资金储备,应对AI大模型研发日益高昂的成本竞争。
来自主题: AI资讯
10210 点击 2026-04-18 07:30
 搜索
搜索
今日,据外媒The Information报道,DeepSeek正首次寻求外部融资,目标估值超过100亿美元(约合人民币681.8亿元)。据多位知情人士透露,DeepSeek已开始与投资人接触,计划融资至少3亿美元(约合人民币20.5亿元),以补充资金储备,应对AI大模型研发日益高昂的成本竞争。
上周 Anthropic 发布 Mythos Preview 的时候,安全圈的反应可以用一个词概括:震惊。
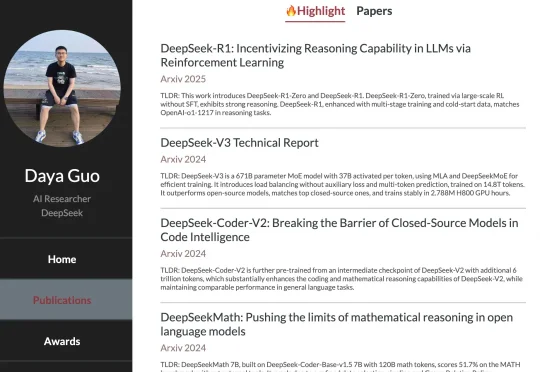
刚刚,图灵联合创始人刘江在海外社交媒体X上透露,DeepSeek核心研究院——郭达雅已加入字节跳动。 郭达雅2023年博士毕业后加入DeepSeek,title是AI Researcher。公开论文显示,从 DeepSeek-Coder、DeepSeek-Math、DeepSeek-Prover、DeepSeek-V3到 DeepSeek-R1,他都出现在核心作者名单中。
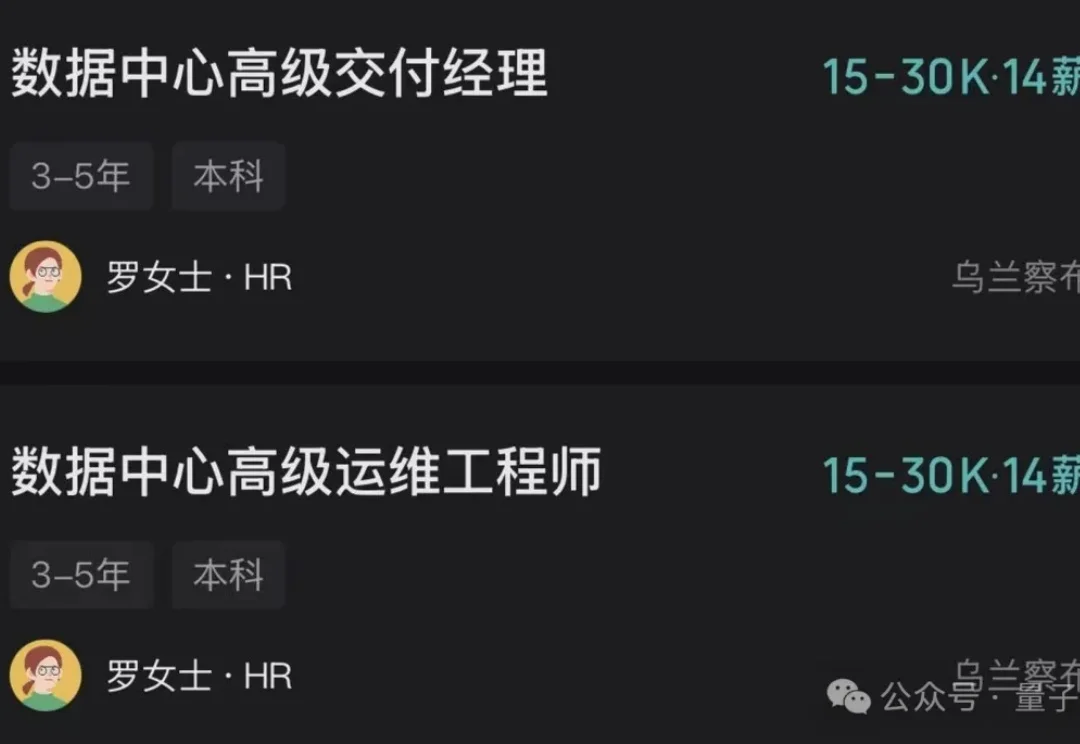
月薪30K,去草原给DeepSeek运维机房。

我每次翻《天龙八部》,翻到少林寺藏经阁那一段,都要停下来。
不更是不更,一更就是个大动作,DeepSeek V4可能真的要来了!

就在大家都急头白脸地等待DeepSeek-V4的时候,冷不丁一篇新论文引起了网友们的注意—— 提出新稀疏注意力机制HISA(分层索引稀疏注意力),突破64K上下文的索引瓶颈,相比DeepSeek正在用的DSA(DeepSeek Sparse Attention)提速2-4倍。

第一篇论文来自字节SEED团队, 打了一些基础; 《Over-Tokenized Transformer》。 论文标题看上去在讨论“过度分词”。 而重点必然是在第二篇上—— DeepSeek公司的学术成果Engram。 《Conditional Memory via Scalable Lookup》 也就是Engram模块所出处的论文。

ICLR论文STEM架构率先提出「查表式记忆」架构,早于DeepSeek Engram三个月。它将Transformer的FFN从动态计算改为静态查表,用token索引的embedding表直接读取记忆,彻底解耦记忆容量与计算开销。

官方宣传语:你是否隐隐担忧,自己或身边的人正在:参与一场席卷所有人的技能大退化?遭受 LLM 诱发的?一个名为 Sam Lavigne 的大学教授,最近发布并开源了一款名为「Slow LLM」的 AI 工具。