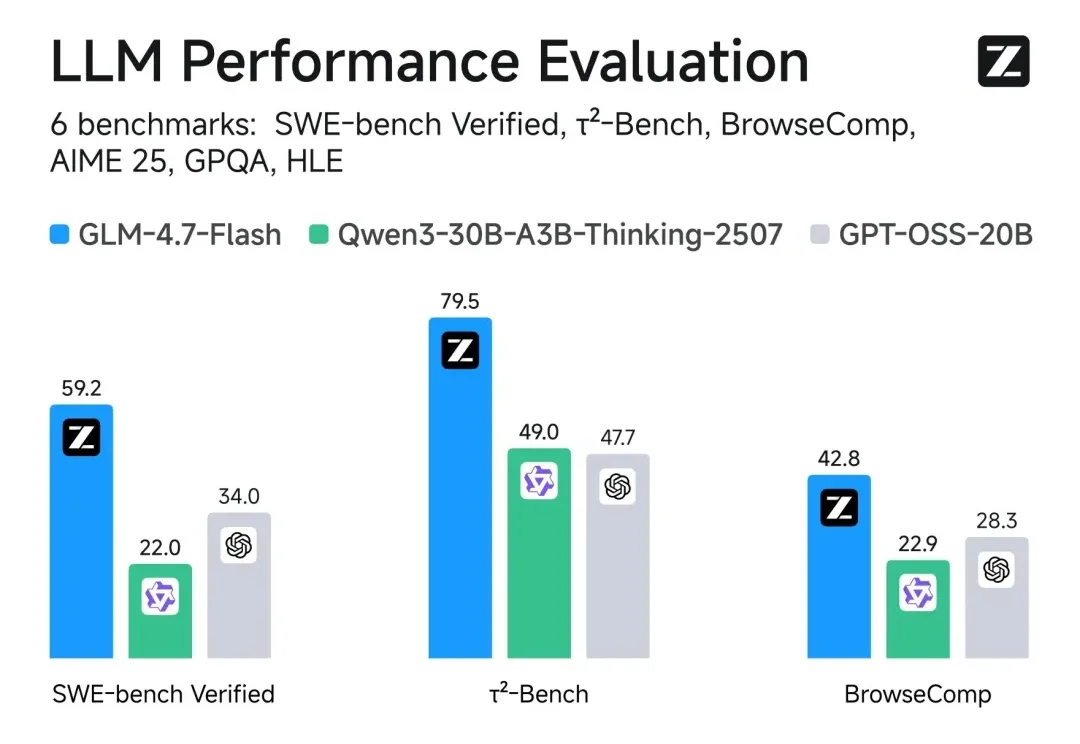
智谱新模型也用DeepSeek的MLA,苹果M5就能跑
智谱新模型也用DeepSeek的MLA,苹果M5就能跑智谱AI上市后,再发新成果。
来自主题: AI资讯
7337 点击 2026-01-21 12:01
 搜索
搜索
智谱AI上市后,再发新成果。

AI变聪明的真相居然是正在“脑内群聊”?!
2025 年 1 月 20 日,DeepSeek(深度求索)正式发布了 DeepSeek-R1 模型,并由此开启了新的开源 LLM 时代。在 Hugging Face 刚刚发布的《「DeepSeek 时刻」一周年记》博客中,DeepSeek-R1 也是该平台上获赞最多的模型。

当 DeepSeek 和 OpenAI 的核心突破者越来越年轻,传统的简历筛选正在失效。一位前阿里达摩院的研究员,试图用 Agent 编织一张能捕捉「下一个 Ilya」的网。

「服务器繁忙,请稍后再试。」

元旦期间,DeepSeek 发布的 mHC 震撼了整个 AI 社区。

面对《the Big Technology Podcast》抛出的问题,Mistral AI的 CEO Arthur Mensch 表示:大模型肯定会走向商品化,当模型表现越来越接近,那么竞争就不在于模型本身,而在于如何让客户用起来。

王潜说,DeepSeek 当然很伟大,但我们要干一个像 OpenAI 那样的公司。

随着AI大模型研发在架构、记忆、存储等等领域的深水区创新,OCR重新成为了技术专项。DeepSeek在研究、智谱在研究、阿里千问和腾讯混元也都在研究……还得是吴恩达老师,火速来了新课程,帮你速通OCR。
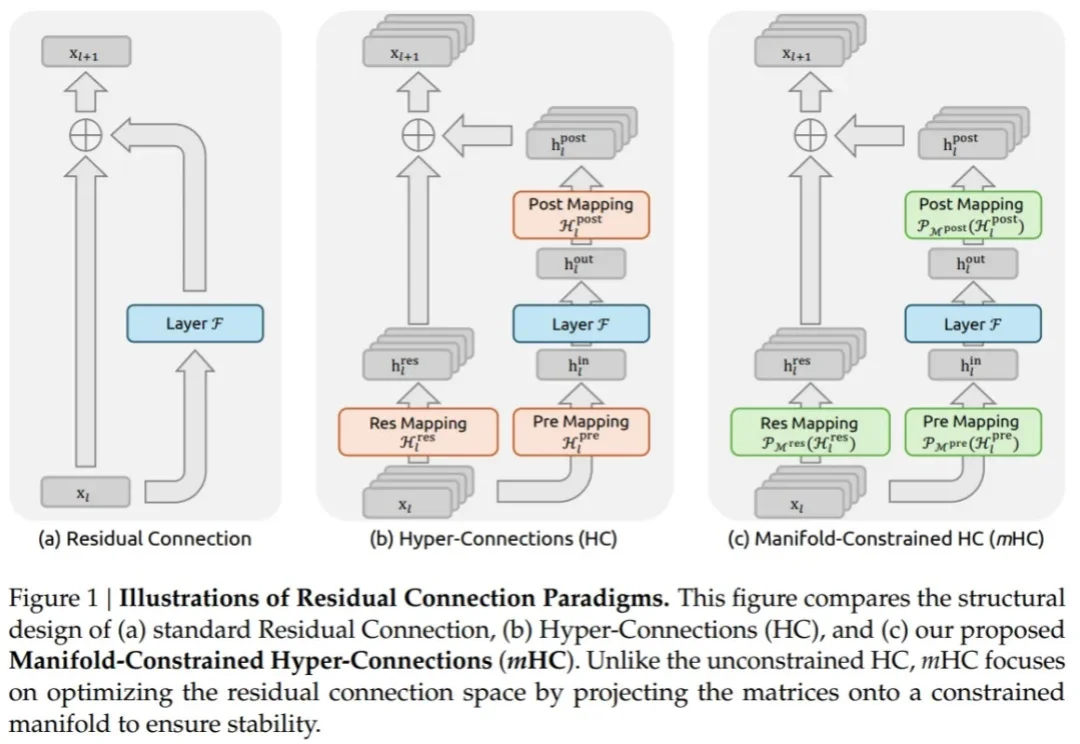
2026 年 1 月过半,我们依然没有等来 DeepSeek V4,但它的模样已经愈发清晰。