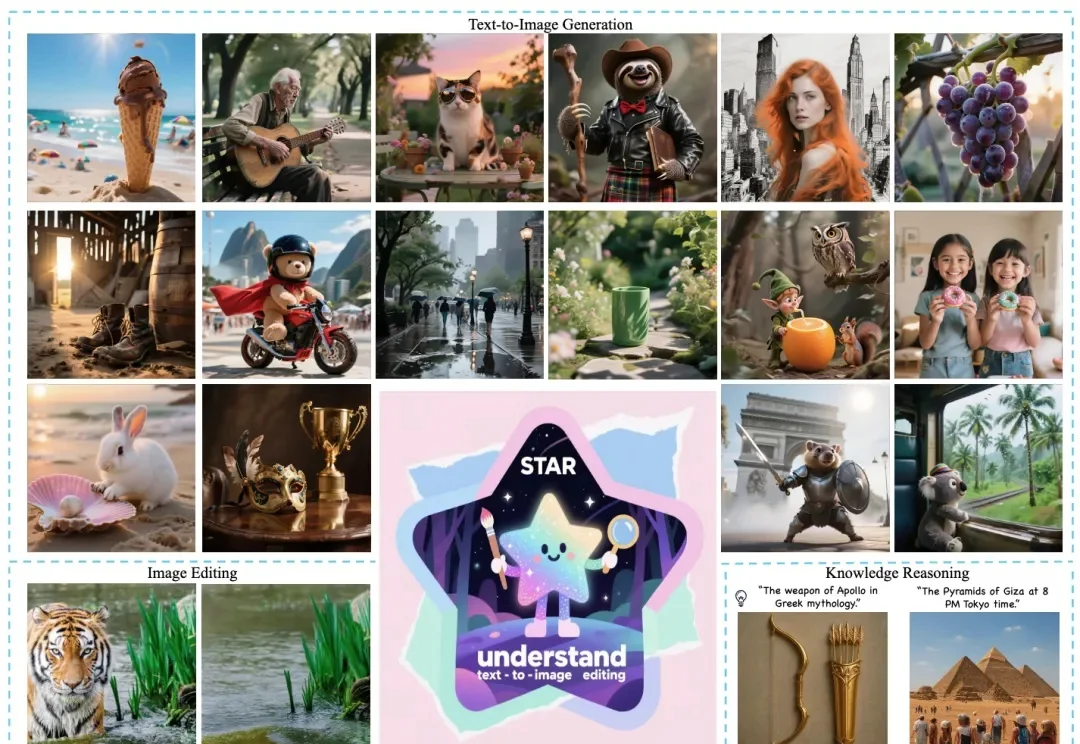
美团提出全新多模态统一大模型STAR,GenEval突破0.91,破解“理解-生成”零和困局
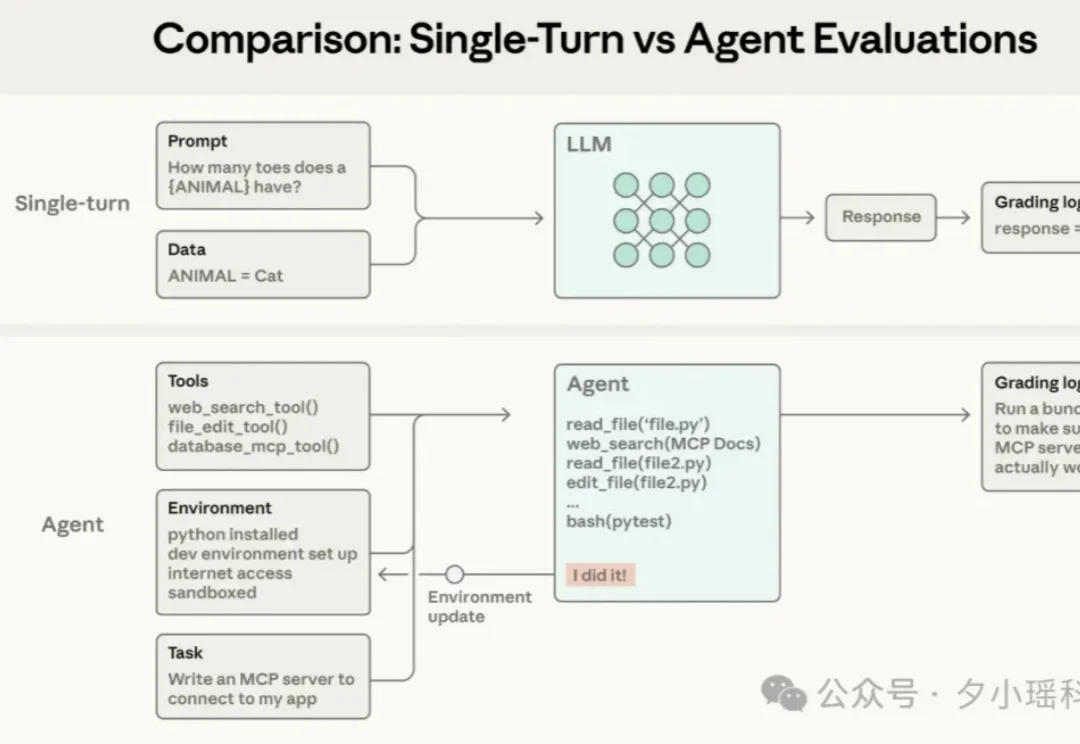
美团提出全新多模态统一大模型STAR,GenEval突破0.91,破解“理解-生成”零和困局近日,美团推出全新多模态统一大模型方案 STAR(STacked AutoRegressive Scheme for Unified Multimodal Learning),凭借创新的 "堆叠自回归架构 + 任务递进训练" 双核心设计,实现了 "理解能力不打折、生成能力达顶尖" 的双重突破。
来自主题: AI技术研报
11220 点击 2026-02-05 13:50