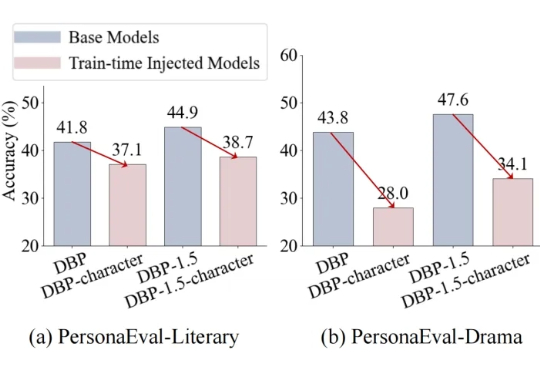
大模型给自己当裁判并不靠谱!上海交通大学新研究揭示LLM-as-a-judge机制缺陷
大模型给自己当裁判并不靠谱!上海交通大学新研究揭示LLM-as-a-judge机制缺陷大语言模型(LLM)正从工具进化为“裁判”(LLM-as-a-judge),开始大规模地评判由AI自己生成的内容。这种高效的评估范式,其可靠性与人类判断的一致性,却很少被深入验证。
来自主题: AI技术研报
7972 点击 2025-08-17 13:16
 搜索
搜索
大语言模型(LLM)正从工具进化为“裁判”(LLM-as-a-judge),开始大规模地评判由AI自己生成的内容。这种高效的评估范式,其可靠性与人类判断的一致性,却很少被深入验证。

中国在人工智能领域已经成为全球竞争的重要力量。根据斯坦福 2025 年 AI 指数报告,美国虽然仍领先于顶级模型数量,但中国正在迅速缩小差距 —— 在 MMLU、HumanEval 等基准测试中的差距已从几乎双位数下降到几乎持平。
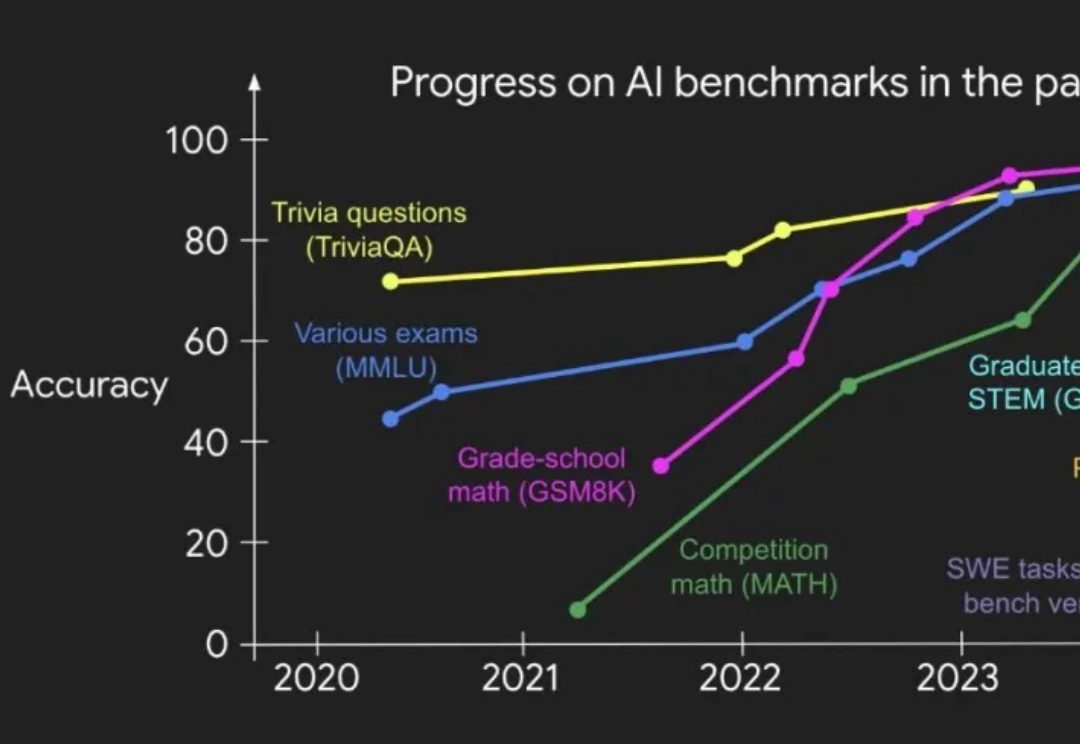
在三个月前,OpenAI 研究员 Shunyu Yao 发表了一篇关于 AI 的下半场的博客引起了广泛讨论。他在博客中指出,AI 研究正在从 “能不能做” 转向 “学得是否有效”,传统的基准测试已经难以衡量 AI 的实际效用,他指出现有的评估方式中,模型被要求独立完成每个任务,然后取平均得分。这种方式忽略了任务之间的连贯性,无法评估模型长期适应能力和更类人的动态学习能力。
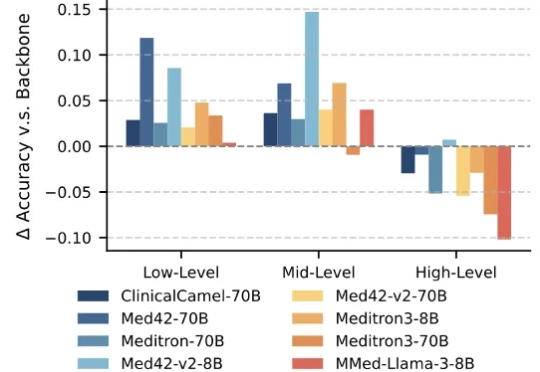
大语言模型(Large Language Models,LLMs)技术的迅猛发展,正在深刻重塑医疗行业。医疗领域正成为这一前沿技术的 “新战场” 之一。大模型具备强大的文本理解与生成能力,能够快速读取医学文献、解读病历记录,甚至基于患者表述生成初步诊断建议,有效辅助医生提升诊断的准确性与效率。
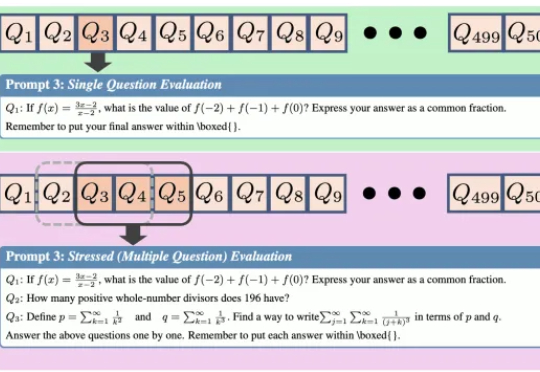
给AI一场压力测试,结果性能暴跌近30%。 来自上海人工智能实验室、清华大学和中国人民大学的研究团队设计了一个全新的“压力测试”框架——REST (Reasoning Evaluation through Simultaneous Testing)。

怎么快速判断一个生成模型好不好? 最直接的办法当然是 —— 去问一位做图像生成、视频生成、或者专门做评测的朋友。他们懂技术、有经验、眼光毒辣,能告诉你模型到底强在哪、弱在哪,适不适合你的需求。
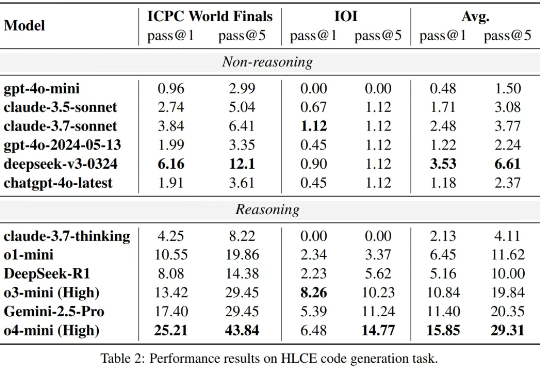
大语言模型(LLM)在标准编程基准测试(如 HumanEval,Livecodebench)上已经接近 “毕业”,但这是否意味着它们已经掌握了人类顶尖水平的复杂推理和编程能力?

几十年来,人工智能领域一直在思考一个看似简单但非常根本的问题: 如果一个智能体要在真实世界中行动、规划,并且和环境互动,它需要一个怎样的「世界模型」?

我们常把LangGraph、RAG、memory、evals等工具比作乐高积木,经验丰富的人知道如何搭配使用,就能迅速解决问题

当前,Agentic RAG(Retrieval-Augmented Generation)正逐步成为大型语言模型访问外部知识的关键路径。但在真实实践中,搜索智能体的强化学习训练并未展现出预期的稳定优势。一方面,部分方法优化的目标与真实下游需求存在偏离,另一方面,搜索器与生成器间的耦合也影响了泛化与部署效率。