
全球百模争霸,国产大模型拿下多个冠军!智源FlagEval全球评测榜单出炉
全球百模争霸,国产大模型拿下多个冠军!智源FlagEval全球评测榜单出炉2024年快要结束了,世界大模型究竟孰强孰弱?刚刚,智源研究院发布了下半年大模型综合评测结果,涵盖了开源闭源100+模型,横跨文本、语音、图像和视频等多个领域。
来自主题: AI资讯
8941 点击 2024-12-20 15:12
 搜索
搜索
2024年快要结束了,世界大模型究竟孰强孰弱?刚刚,智源研究院发布了下半年大模型综合评测结果,涵盖了开源闭源100+模型,横跨文本、语音、图像和视频等多个领域。

2024年12月19日,智源研究院发布并解读国内外100余个开源和商业闭源的语言、视觉语言、文生图、文生视频、语音语言大模型综合及专项评测结果。
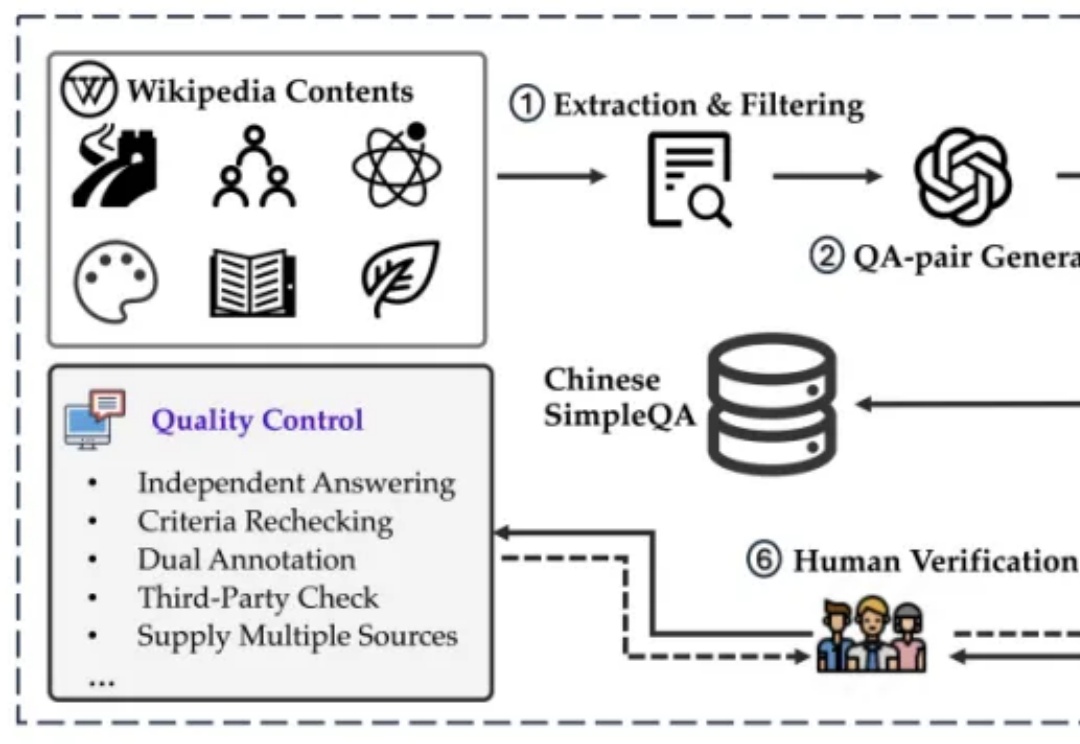
如何解决模型生成幻觉一直是人工智能(AI)领域的一个悬而未解的问题。为了测量语言模型的事实正确性,近期 OpenAI 发布并开源了一个名为 SimpleQA 的评测集。而我们也同样一直在关注模型事实正确性这一领域,目前该领域存在数据过时、评测不准和覆盖不全等问题。例如现在大家广泛使用的知识评测集还是 CommonSenseQA、CMMLU 和 C-Eval 等选择题形式的评测集。

清华大学NLP实验室联合北京师范大学、中国科学院大学、东北大学等机构的研究人员推出了全新的评测方法 RAGEval,通过快速构建场景化评估数据实现对检索增强生成(RAG)系统的“精准诊断”。
让 LLM 在自我进化时也能保持对齐。

2024年10月24日,全球生命科学行业云软件领导者Veeva Systems (NYSE: VEEV) 在上海举“2024 Veeva中国商务峰会”,活动现场,Veeva宣布了其基于中国市场洞察的一系列业务进展。

TL;DR:DuoAttention 通过将大语言模型的注意力头分为检索头(Retrieval Heads,需要完整 KV 缓存)和流式头(Streaming Heads,只需固定量 KV 缓存),大幅提升了长上下文推理的效率,显著减少内存消耗、同时提高解码(Decoding)和预填充(Pre-filling)速度,同时在长短上下文任务中保持了准确率。

随着对现有互联网数据的预训练逐渐成熟,研究的探索空间正由预训练转向后期训练(Post-training),OpenAI o1 的发布正彰显了这一点。

RAG(Retrieval-Augmented Generation)是一种结合信息检索与文本生成的技术,旨在提高大型语言模型(LLM)在回答复杂查询时的表现。它通过检索相关的上下文信息来增强生成答案的质量和准确性。解读RAG测评:关键指标与应用分析

在AI的世界里,模型的评估往往被看作是最后的「检查点」,但事实上,它应该是确保AI模型适合其目标的基础。