三个LLM顶一个OpenAI?2亿条性能记录加持,路由n个「小」模型逆袭
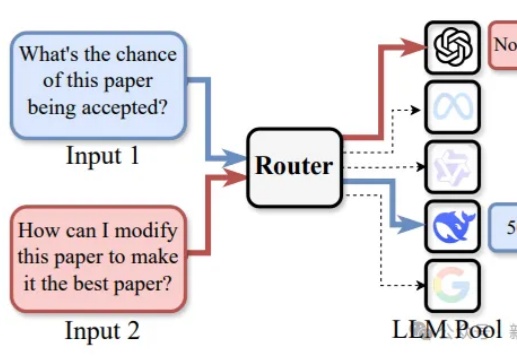
三个LLM顶一个OpenAI?2亿条性能记录加持,路由n个「小」模型逆袭路由LLM是指一种通过router动态分配请求到若干候选LLM的机制。论文提出且开源了针对router设计的全面RouterEval基准,通过整合8500+个LLM在12个主流Benchmark上的2亿条性能记录。将大模型路由问题转化为标准的分类任务,使研究者可在单卡甚至笔记本电脑上开展前沿研究。
来自主题: AI技术研报
6775 点击 2025-04-08 14:26