OpenAI新模型突破10项菲尔兹奖级难题/AI女团选秀9个出道成团/最强AI 画不好《蒙娜丽莎》|Hunt Good周报
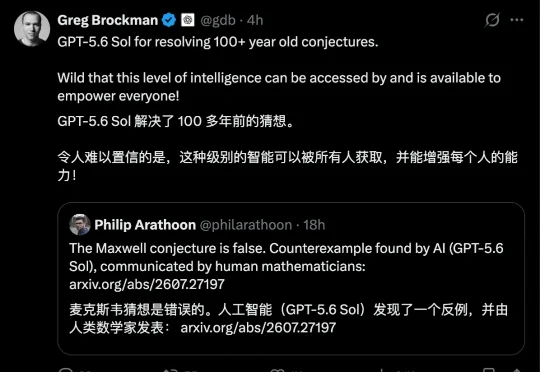
OpenAI新模型突破10项菲尔兹奖级难题/AI女团选秀9个出道成团/最强AI 画不好《蒙娜丽莎》|Hunt Good周报GPT-5.6 Sol 推翻 100 多年前的麦克斯韦猜想,下一代模型突破 10 个!数学家菲利普·阿拉图恩、加文·鲍尔和马修·D·克瓦尔海姆于 2026 年 7 月 29 日在 arXiv 上发表论文,提到由 GPT-5.6 Sol 找到了一个反例,证明了 100 多年前的麦克斯韦猜想是假的。
来自主题: AI资讯
9207 点击 2026-08-02 12:03