
硬刚Sora 2,马斯克发视频大模型,免费可玩,前英伟达何宜晖参与
硬刚Sora 2,马斯克发视频大模型,免费可玩,前英伟达何宜晖参与今天凌晨,马斯克的大模型独角兽xAI祭出最新视频生成模型Imagine v0.9,免费向所有用户开放。一周前,OpenAI发布了旗舰视频和音频生成模型Sora 2,此次更新或许是马斯克对Sora 2的直接回应。
来自主题: AI资讯
9185 点击 2025-10-08 22:35
 搜索
搜索
今天凌晨,马斯克的大模型独角兽xAI祭出最新视频生成模型Imagine v0.9,免费向所有用户开放。一周前,OpenAI发布了旗舰视频和音频生成模型Sora 2,此次更新或许是马斯克对Sora 2的直接回应。
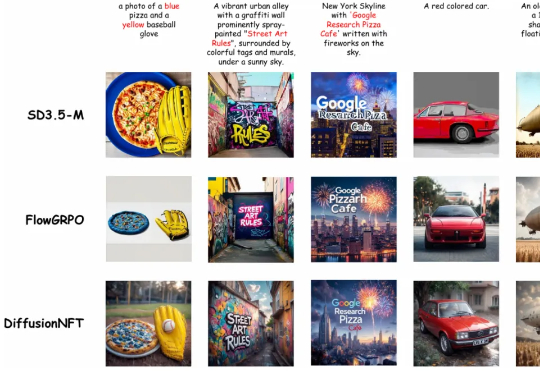
清华大学朱军教授团队,NVIDIA Deep Imagination 研究组与斯坦福 Stefano Ermon 团队联合提出了一种全新的扩散模型强化学习(RL)范式 ——Diffusion Negative-aware FineTuning (DiffusionNFT)。该方法首次突破现有 RL 对扩散模型的基本假设,直接在前向加噪过程(forward process)上进行优化
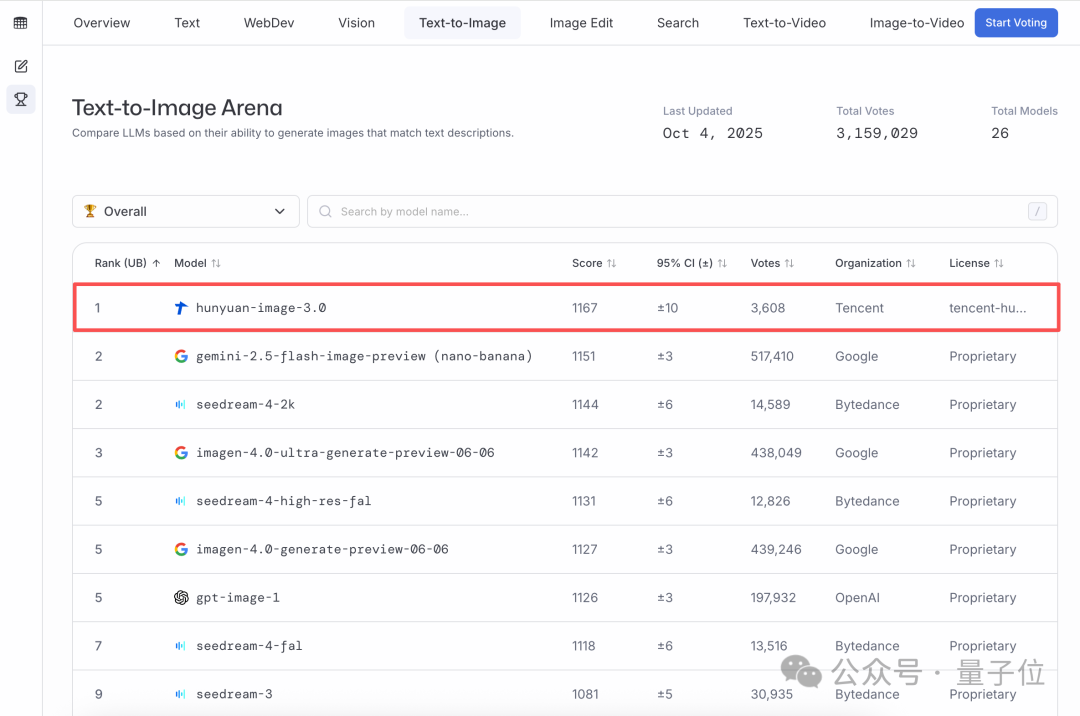
全球文生图大模型王座,易主了。就在刚刚,LMArena竞技场发布了最新的文生图榜单,第一名来自中国,属于腾讯混元图像3.0!不仅超越了谷歌的Nano Banana,也超越了字节的Seedream和OpenAI的gpt-Image,在全球26个大模型中稳居第一。
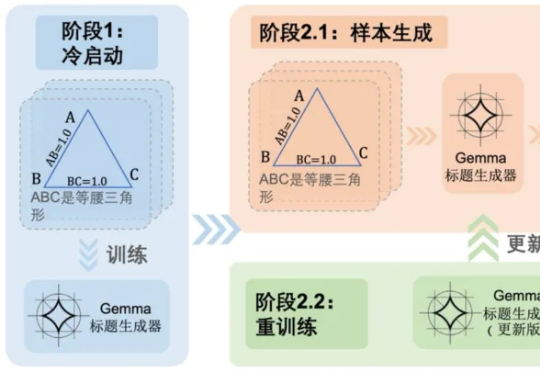
随着多模态大语言模型(MLLMs)在视觉问答、图像描述等任务中的广泛应用,其推理能力尤其是数学几何问题的解决能力,逐渐成为研究热点。 然而,现有方法大多依赖模板生成图像 - 文本对,泛化能力有限,且视
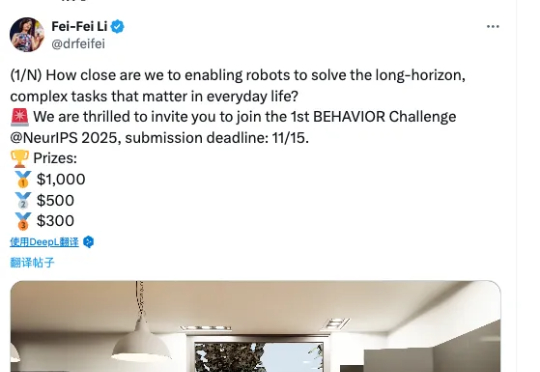
答案或许渐渐清晰。李飞飞团队与斯坦福 AI 实验室正式官宣:首届 BEHAVIOR 挑战赛将登陆 NeurIPS 2025。这是一个为具身智能量身定制的 “超级 benchmark”,涵盖真实家庭场景下最关键的 1000 个日常任务(烹饪、清洁、整理……),并首次以 50 个完整长时段任务作为核心赛题,考验机器人能否在逼真的虚拟环境中完成真正贴近人类生活的操作。

刚刚,Qwen推出了新图像编辑模型——Qwen-Image-Edit-2509。不仅支持多图融合,提供“人物+人物”,“人物+商品”,“人物+场景” 等多种玩法,还增强了人物、商品、文字等单图一致性。
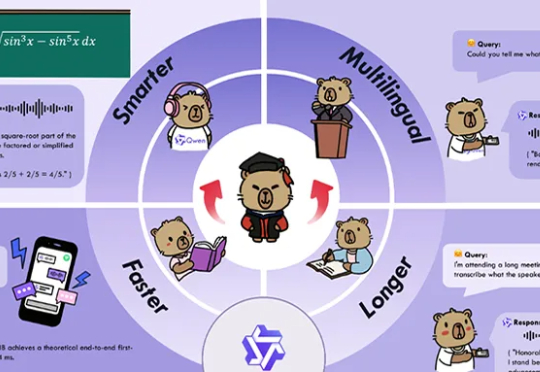
深夜,阿里通义大模型团队连放三个大招:开源原生全模态大模型Qwen3-Omni、语音生成模型Qwen3-TTS、图像编辑模型Qwen-Image-Edit-2509更新。Qwen3-Omni能无缝处理文本、图像、音频和视频等多种输入形式,并通过实时流式响应同时生成文本与自然语音输出。

谷歌这只「香蕉」火得有些疯狂:Nano Banana(即 Gemini 2.5 Flash Image)自 8 月底上线以来,仅用几周就吸引了超过 1,000 万新用户,并在 Gemini 应用中完成了 2 亿次图像编辑请求

GPT-5 的发布,可以看作是一个分水岭。练习时长两年半的 GPT-5,并没有展现出和 GPT-4 本质上的差别,甚至因为模型的预设人格引发了用户的反感情绪。
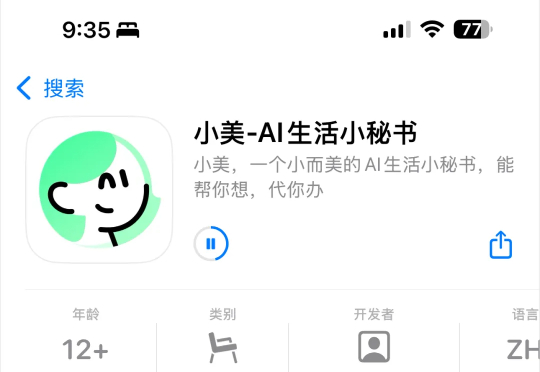
啊?今天早上9点多的时候。 美团上线了他们的首个生活类Agent。 名字,叫小美。 大厂们卷疯了。 这战场,真的从WAIMAI打到了AI了我靠。 而且还真的居然被我猜中了。 我上周写过美团的开源大模型