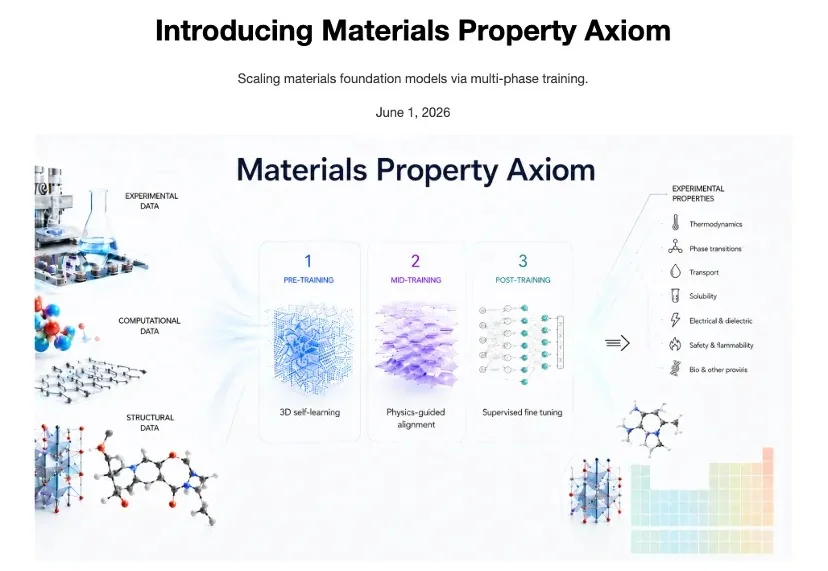
AGI将至!40项实验全面SOTA,超级递归智能体自主打造最强材料基座模型
AGI将至!40项实验全面SOTA,超级递归智能体自主打造最强材料基座模型今年,我们正在打开 AI 自我进化的大门,按下了通往 AGI 的加速键。
来自主题: AI技术研报
6069 点击 2026-06-02 15:23
 搜索
搜索
今年,我们正在打开 AI 自我进化的大门,按下了通往 AGI 的加速键。

把一件皱成一团的衣服叠好,是家务,也是机器人操作里的“硬仗”。

2026 年初,各大 AI 厂商在上下文窗口长度上展开激烈角逐。Google 的 Gemini 3 Pro 已支持 100 万级 token 上下文,Meta 的 Llama 4 Scout 更宣称可处理 1000 万 token。GPT-5 系列也在快速推进长上下文能力。

AI模型在电脑上预测精度爆表,一到实验室就各种出错用不了?
核心观点:由前Apple Vision Pro两位技术负责人联合创办的Reactor,近期完成5900万美元种子轮及A轮融资,由Lightspeed Venture Partners领投,WndrCo

MiniMax M3 今日正式发布。MiniMax M3 在编程和智能体等专业任务上达到了前沿的能力。它使用了我们提出的全新注意力架构 MSA (MiniMax Sparse Attention),最高支持 1M 超长上下文。如外界所期待的那样,它也是一个原生多模态模型,支持图片和视频的输入,并能操作电脑桌面。

今天,扣子 3.0 正式上线,扣子手机端 (iOS / Android)、电脑端(Mac OS / Windows)、网页端(coze.cn)三端全量更新。这一次,扣子带来了全新电脑端,扣子 App 也全面升级,我们把 Agent 带进了更完整的工作现场:

刚刚,The Information 曝光了 Meta 内部备忘录、说明年春天要推出一款 AI 吊坠,我的第一反应大概是,又来?但我发现,不只是 Meta,在之前苹果和 OpenAI 曝光的AI 硬件计划,你会发现那个两年前被判死刑的脖挂形态,正被行业巨头再次捡回来。

Helio 做的是 AI Native Workforce——让 AI 同事成为团队的原住民。在 Helio 里,AI 不是侧边栏的助手按钮,不是输入框对面的服务员,而是坐你旁边工位的同事——拥有自己的名字、头像、邮箱,和真人一起出现在组织联系人列表里。
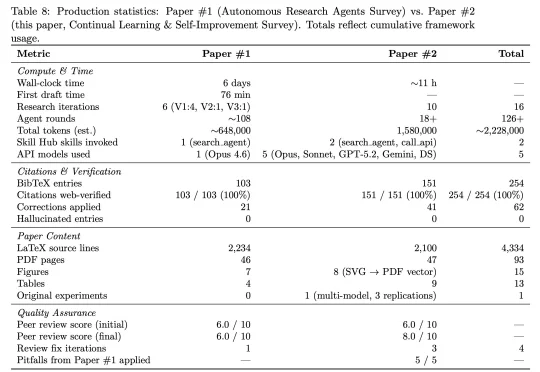
DeepSeek 研究员陈德里(Deli Chen)和 AI 合作的第二篇论文来了!论文地址:https://victorchen96.github.io/continual_learning_survey.pdf这篇论文聚焦 continual learning(持续学习) 与 self-iteration(自我迭代)。在陈德里看来,这是 AI 迈向 AGI 过程中极为关键的一步。