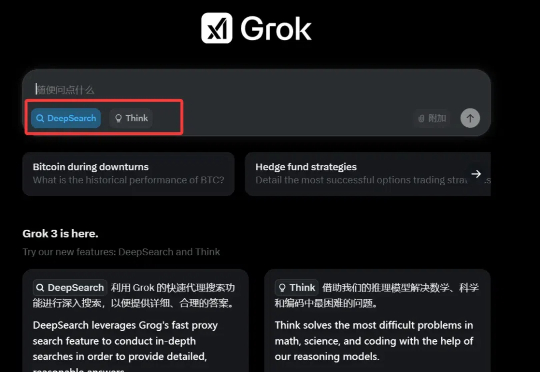
地表最强Grok3突袭免费体验,网友实测对比DeepSeek,发现中文彩蛋
地表最强Grok3突袭免费体验,网友实测对比DeepSeek,发现中文彩蛋又是一个文理兼修的优等生,能薅一点是一点。堆了 20 万张 GPU、号称「地表最强」大模型 Grok-3 已经可用啦。「 Grok 3 + Thinking 感觉与 OpenAI 最强商用模型(o1-pro,200 美元/月)的顶尖水平相差无几,
来自主题: AI资讯
9006 点击 2025-02-20 16:16
 搜索
搜索
又是一个文理兼修的优等生,能薅一点是一点。堆了 20 万张 GPU、号称「地表最强」大模型 Grok-3 已经可用啦。「 Grok 3 + Thinking 感觉与 OpenAI 最强商用模型(o1-pro,200 美元/月)的顶尖水平相差无几,

OpenAI刚刚发布SWE-Lancer编码基准测试,直接让AI模型挑战真实外包任务!这些任务总价值高达100万美元。有趣的是,测试结果显示,Anthropic的Claude 3.5 Sonnet在「赚钱」能力上竟然超越了OpenAI自家的GPT-4o和o1模型。
这个AI领域千亿级市场,将辐射千家万户。 DeepSeek-R1横空出世,打响了大模型比拼性价比的第一枪。 Meta、OpenAI等国外头部大模型厂商纷纷复刻或变相降价。比DeepSeek-R1晚两周发布的OpenAI o3-mini模型,定价比前代模型o1-mini降低了超6成,比前代完整版的o1模型便宜超9成。

大模型混战,一边卷能力,一边卷“低价”。 DeepSeek彻底让全球都坐不住了。 昨天,马斯克携“地球上最聪明的AI”——Gork 3在直播中亮相,自称其“推理能力超越目前所有已知模型”,在推理-测试时间得分上,也好于DeepSeek R1、OpenAI o1。不久前,国民级应用微信宣布接入DeepSeek R1,正在灰度测试中,这一王炸组合被外界认为AI搜索领域要变天。
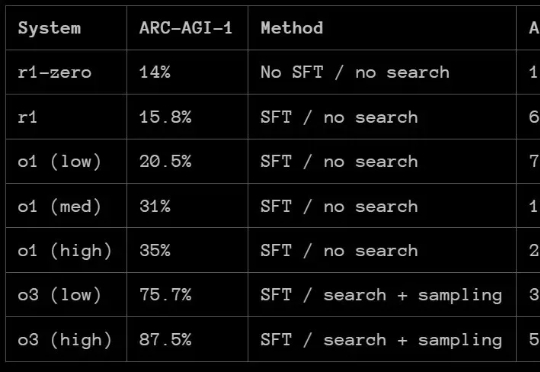
那么,DeepSeek-R1 的 ARC-AGI 成绩如何呢?根据 ARC Prize 发布的报告,R1 在 ARC-AGI-1 上的表现还赶不上 OpenAI 的 o1 系列模型,更别说 o3 系列了。但 DeepSeek-R1 也有自己的特有优势:成本低。
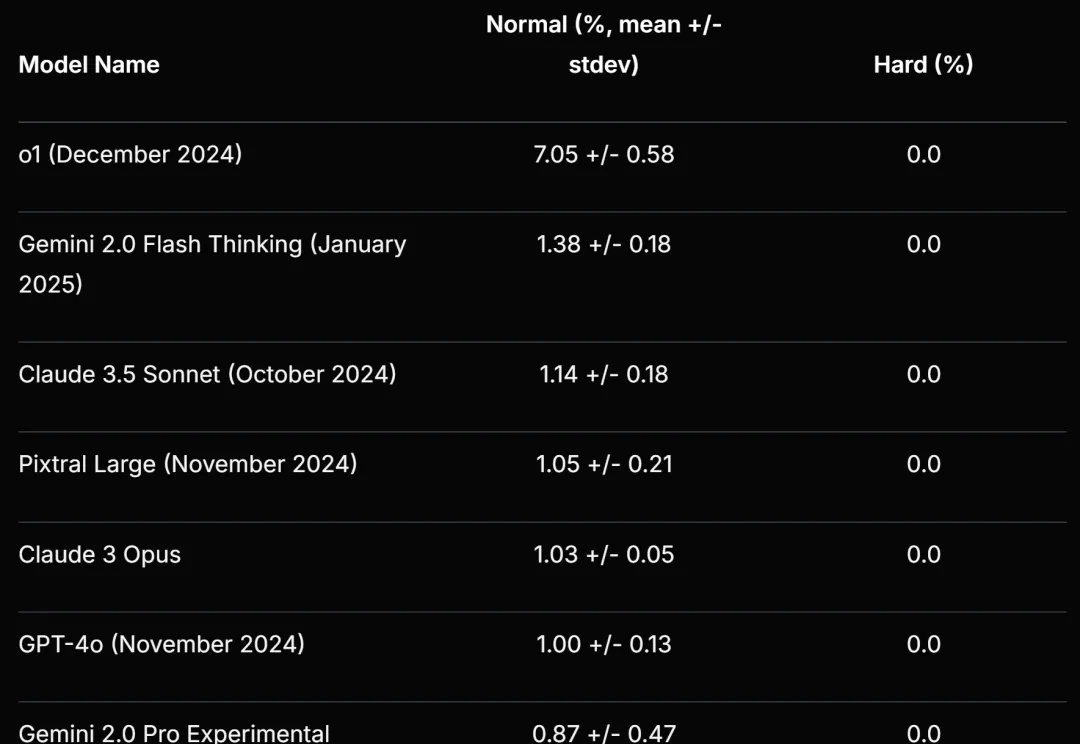
Scale AI 等提出的新基准再次暴露了大语言模型的弱点。
让DeepSeek代替Claude思考,缝合怪玩法火了。原因无它:比单独使用DeepSeek R1、Claude Sonnet 3.5、OpenAI o1模型的效果更好。DeepClaude应用本身100%免费且开源,在GitHub上已揽获3k星星(当然API要用自己的)。

【新智元导读】仅凭测试时Scaling,1B模型竟完胜405B!多机构联手巧妙应用计算最优TTS策略,不仅0.5B模型在数学任务上碾压GPT-4o,7B模型更是力压o1、DeepSeek R1这样的顶尖选手。
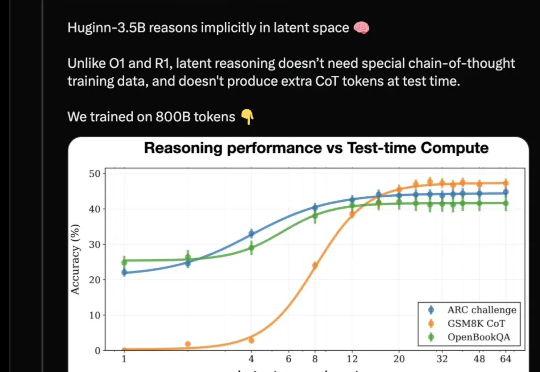
开源推理大模型新架构来了,采用与Deepseek-R1/OpenAI o1截然不同的路线: 抛弃长思维链和人类的语言,直接在连续的高维潜空间用隐藏状态推理,可自适应地花费更多计算来思考更长时间。

推理大语言模型(LLM),如 OpenAI 的 o1 系列、Google 的 Gemini、DeepSeek 和 Qwen-QwQ 等,通过模拟人类推理过程,在多个专业领域已超越人类专家,并通过延长推理时间提高准确性。推理模型的核心技术包括强化学习(Reinforcement Learning)和推理规模(Inference scaling)。