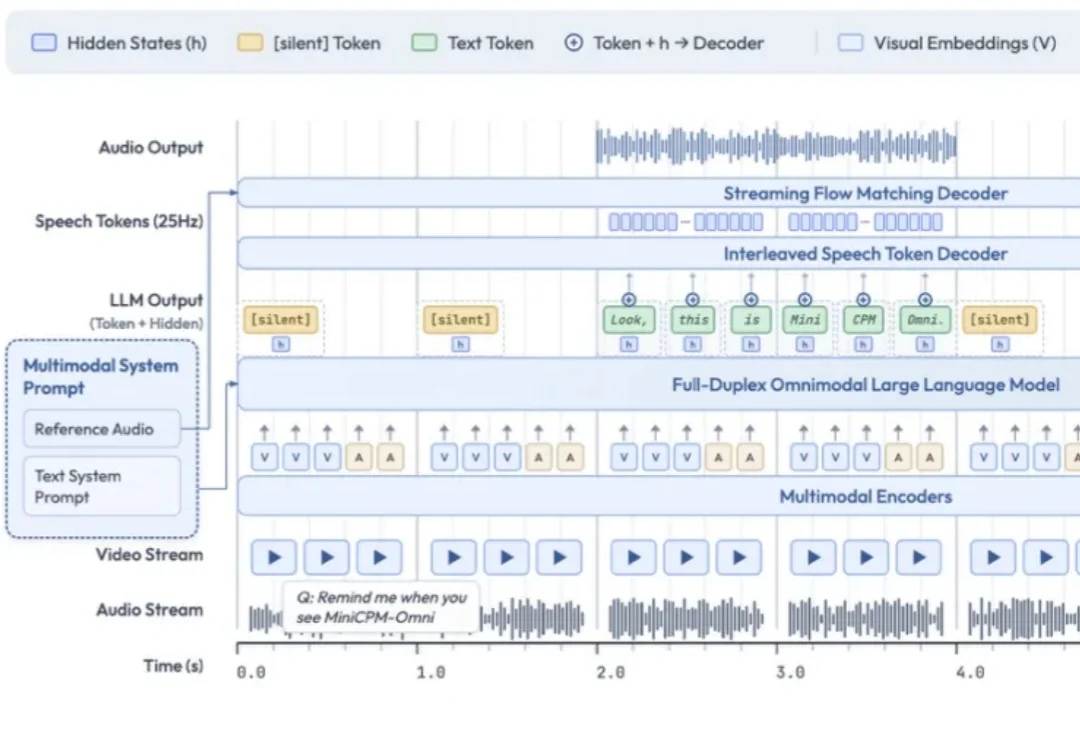
AI能帮忙厨房看火了!面壁智能开源全模态模型MiniCPM-o4.5,边看边听还能主动抢答
AI能帮忙厨房看火了!面壁智能开源全模态模型MiniCPM-o4.5,边看边听还能主动抢答空气炸锅“叮”了一声。
来自主题: AI资讯
8708 点击 2026-02-05 14:23
 搜索
搜索
空气炸锅“叮”了一声。

今天 ,OpenAI 开源了俩模型:120B/20B 117B 的 gpt-oss-120b 对标 o4-min,按官方说法至少需要 80G 内存,推荐使用单卡 H100 GPU 而刚买的的游戏本,刚好满足gpt-oss-120b 的部署条件

第二轮首届大模型对抗赛结果出炉了!o3轻而易举击败o4-mini,拿下100%胜率。Grok 4和Gemini 2.5 Pro激烈对决,最终在加赛中Grok 4成功晋级。明日,Grok 4和o3将迎来终局之战。
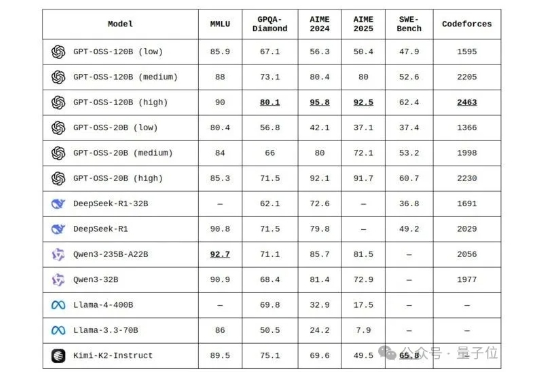
全网开扒GPT-oss,惊喜发现…… 奥特曼还是谦虚了,这性能岂止是o4-mini的水平,直接SOTA击穿一众开源模型。
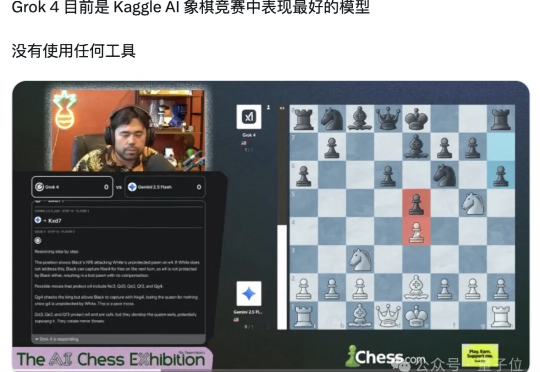
最新战报最新战报:首届AI国际象棋对战……马斯克家的Grok 4“遥遥领先”了。 是的,谷歌给大模型整了个国际象棋比赛:Kaggle AI象棋竞赛。

今天凌晨,OpenAI 甩出一对王炸,正式发布两款开源模型:gpt-oss-120b 和 gpt-oss-20b。是的,你没看错,那个曾经被戏称为 CloseAI 的男人,带着他的诚意,回来了!
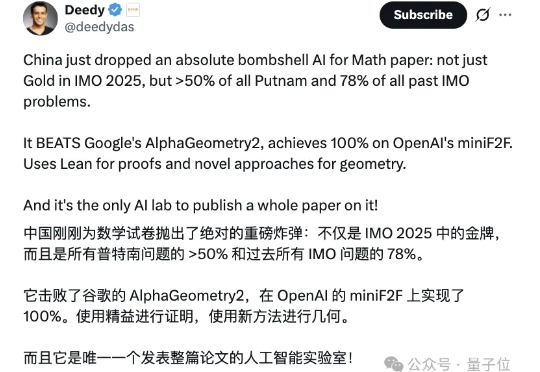
不仅能达IMO银牌水准,更能解决普特南数学竞赛难题,甚至超越顶尖模型o4-mini! 字节发布全新复杂数学解决模型——Seed-Prover。
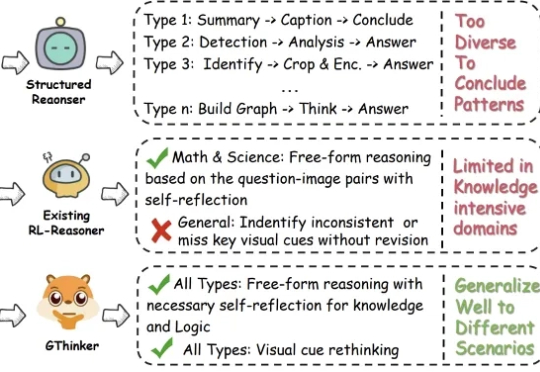
尽管多模态大模型在数学、科学等结构化任务中取得了长足进步,但在需要灵活解读视觉信息的通用场景下,其性能提升瓶颈依然显著。
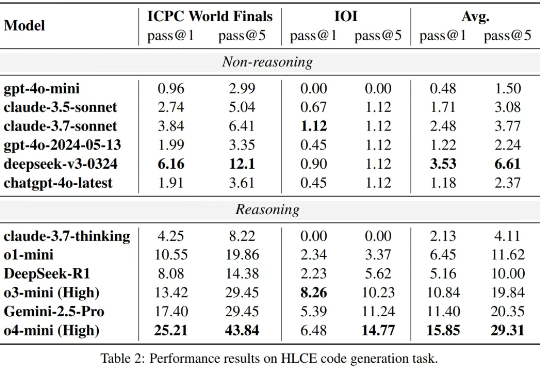
大语言模型(LLM)在标准编程基准测试(如 HumanEval,Livecodebench)上已经接近 “毕业”,但这是否意味着它们已经掌握了人类顶尖水平的复杂推理和编程能力?
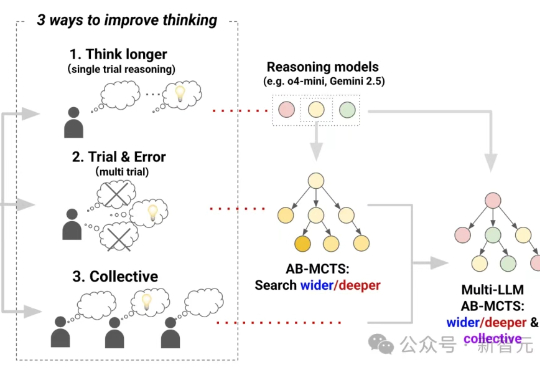
三个前沿AI能融合成AGI吗?Sakana AI提出Multi-LLM AB-MCTS方法,整合o4-mini、Gemini-2.5-Pro与DeepSeek-R1-0528模型,在推理过程中动态协作,通过试错优化生成过程,有效融合群体AI智慧。